 |
|
Die vorliegende Version des Textes unterscheidet sich nicht wesentlich von der vom 9. bis zum 30.5.2003 bei Telepolis veröffentlichten Variante. Einige Tipp- und Stilfehler wurden korrigiert. Sollten Sie auf Fehler im Text stoßen, schicken Sie mir bitte eine Mail. Inhaltliche Ergänzungen oder Aktualisierungen beabsichtige ich jedoch nicht vorzunehmen.
Das Wiki-Prinzip
Tanz der Gehirne - Teil 1
Weitgehend unbemerkt von der Medienöffentlichkeit arbeiten Tausende von Freiwilligen an einer Enzyklopädie ungekannter Größe. Die Inhalte stehen unter einer Copyleft-Lizenz, sind also beliebig nutzbar, solange veränderte Versionen ebenfalls frei sind. Menschen aus der vernetzten Welt haben in zahlreichen Sprachen bereits fast 200.000 Artikel verfasst, das Themenspektrum deckt alle Bereiche menschlichen Daseins ab. Wikipedia, "die freie Enzyklopädie", ist der bisherige Höhepunkt der Wiki-Entwicklung - und vielleicht der Beginn einer neuen Internet-Ära.
Lange Zeit fristeten Wikis im Internet ein Schattendasein. Wer darüber stolperte, nahm die merkwürdige Syntax, das altertümliche Design und den fremdartigen Jargon zur Kenntnis, las vielleicht noch kurz eine Zusammenfassung des Prinzips - "jeder kann alles editieren" - und surfte dann kopfschüttelnd weiter. Doch die Wiki Wiki Webs wollten einfach nicht verschwinden. Mehr und mehr Communities von Wiki-Anhängern formierten sich um jedes nur erdenkliche Thema.
|
Die dokumentierte Geschichte der Wikis beginnt am 16. März 1995 mit einer Email von Ward Cunningham, einem Software-Designer aus Portland, Oregon, an einen gewissen Steve P.:
"Steve - ich habe eine neue Datenbank auf meinem Web-Server installiert und bitte Dich, mal einen Blick darauf zu werfen. Es ist ein Web von Menschen, Projekten und Mustern, auf das man über ein cgi-bin-Skript zugreifen kann. Es bietet die Möglichkeit, ohne HTML-Kenntnisse mit Formularen Text zu editieren. Es wäre schön, wenn Du mitmachen oder wenigstens Deinen Namen in der Liste der RecentVisitors eintragen könntest .. Die URL ist http://c2.com/cgi-bin/wiki - danke schön und beste Grüße."
Cunningham beschäftigte sich schon länger mit sogenannten Entwurfsmustern (Patterns) - in der Software-Entwicklung sind das möglichst allgemeine Standardlösungen für wiederkehrende Probleme, z.B. "Anordnung von Objekten in einer Baumhierachie". Um solche Muster zu sammeln und zu verfeinern, bot es sich an, mit Entwicklern aus aller Welt zusammen zu arbeiten. So erweiterte Cunningham sein "Portland Pattern Repository" um eine Datenbank für Entwurfsmuster, die er WikiWikiWeb nannte.
"Wiki Wiki", das bedeutet "schnell" auf Hawaiianisch. Schnell sollte es gehen, die neue Datenbank mit Inhalten zu füllen. Als alternativer Name stand "QuickWeb" zur Disposition, doch in Anlehnung an das noch junge WWW gefiel dem Entwickler die Alliteration besser. Wäre die Entscheidung anders gefallen, würde Wikipedia heute vielleicht Quickipedia heißen ...
Angriff der Killer-Kamele
Das Prinzip hinter der neu gegründeten Musterdatenbank war einfach, aber genial: Unter jeder Seite befindet sich ein "EditText"-Link, der es erlaubt, den Text der Seite direkt im Browser zu bearbeiten. Doch wie Cunningham in seiner Email schrieb, sollten sich die Autoren nicht mit HTML, der Beschreibungssprache für WWW-Seiten, herumquälen müssen. Statt dessen entwickelte er eine vereinfachte Syntax, die von der Wiki-Software in HTML umgewandelt wird. Text kann unformatiert eingegeben werden, möchte man Überschriften, Hervorhebungen usw. einsetzen, muss man ein paar Regeln lernen (z.B. "== Abc ==" für Überschriften ersten Grades).
Um auch das Setzen von Verweisen auf andere Seiten zu ermöglichen, erfand Cunningham ein Schema namens "CamelCase" (wegen der Großbuchstaben, die wie Kamelbuckel hervorstehen). Zeichenfolgen, die einen Großbuchstaben am Anfang und innerhalb der Folge enthalten - z.B. "WikiWiki", "DesignPattern" - werden als Verweise auf andere Seiten mit diesem Namen interpretiert. Existiert die Seite noch nicht, kann sie durch Anklicken eines kleinen Fragezeichens neben dem Link angelegt werden. Da man eine Seite erst auf einer anderen Seite eintragen muss, um sie anzulegen, ist sichergestellt, dass neue Seiten mit bereits im Wiki vorhandenen vernetzt werden.
Jedes Wiki, das die CamelCase-Syntax verwendet, enthält also Hunderte oder Tausende von Seiten mit Worten und Titeln in dieser Form. Benutzer unterschreiben Bemerkungen mit ihrem Namen in CamelCase-Form - aus Ward Cunningham wird z.B. WardCunningham. Und weil ein einzelnes Wort noch keinen Link macht, wird entweder ein Großbuchstabe eingefügt - aus "Evolution" wird "EvoLution" - oder ein Wort angefügt - "EvolutionTheory". Durch CamelCase verstümmelte Worte gelten als "UgLy" (hässlich).
Sabotage-Prävention
"Ugly", das ist auch die Reputation, die Wikis seit langem anhaftet. Unformatierte Seiten voller Worte in Kamelform mit kreuz und quer eingefügten Kommentaren offenbarten sich neuen Besuchern. Ein harter Kern von Fans bildete sich und erweiterte die Musterbank dennoch fleißig, und schon bald schossen andere Wikis wie Pilze aus dem Boden. Neben einer meist ähnlichen Formatierungs-Syntax weisen fast alle Wikis verschiedene Merkmale auf:
Einige Wikis erlauben das Anlegen von Unterseiten, die Seite "TelePolis" könnte also z.B. die Unterseite "BestOf" enthalten.
Die meisten Wikis ermöglichen das Editieren ohne vorherige Anmeldung. Dauerhaft beschädigen kann man in Wikis kaum etwas - eine verunstaltete Seite wird meist relativ schnell wieder restauriert, wenn jemand die Änderung in den RecentChanges sieht. Dazu wird einfach eine vorherige Version editiert und gespeichert. Weniger gut funktioniert dieses Prinzip in toten Wikis, wo sich niemand um Änderungen kümmert. Aber es kommt natürlich auch vor, dass in aktiven Wikis unerwünschte Edits unter den Tisch fallen - in diesem Fall dauert die Reparatur, bis jemand die entsprechende Seite erneut liest.
Die wundersame Welt der Wikis
Insgesamt gibt es über 100 verschiedene "Engines" zum Betrieb eines Wikis, eine stets aktuelle Liste findet sich natürlich im Original-Wiki. Die meisten Wiki-Engines sind Open-Source-Software unter einer entsprechenden Lizenz.
Mit den von Nutzern eingespielten Inhalten ist es anders: Hier gibt es bei den wenigsten Wikis explizite Regeln, womit eine gewisse Rechtsunsicherheit besteht. Eine Weitergabe in anderen Medien ist dann in jedem Fall ohne Erlaubnis der Autoren unzulässig, eine Erlaubnis zur Bearbeitung innerhalb des Wikis ergibt sich bestenfalls implizit aus dessen Funktion.
Wer selbst ein kleines Wiki betreiben möchte, ist mit einer einfachen Lösung wie UseModWiki gut bedient. Das UseMod-Projekt hatte ursprünglich das Ziel, ein offenes Moderations- und Bewertungsforum für das Diskussionsnetz UseNet zu schaffen, entwickelte sich jedoch zum Allzweck-Wiki, das auf Dutzenden Websites zum Einsatz kommt.
Mittlerweile gibt es Wikis für jedes erdenkliche Thema. Wer möchte, kann im virtuellen Reisebus eine Community nach der anderen besuchen, aber natürlich gibt es auch eine schnöde Liste. Und da Wiki-User notorische Erbsenzähler sind, führen sie auch eine Liste der größten Wikis. Damit die Wikis nicht völlig voneinander isoliert sind, gibt es neben der Reisetour noch sogenannte Interwiki-Links: Innerhalb eines Wikis kann man auf einen Artikel in einem anderen verweisen, indem man einen Präfix - wie etwa "WikiPedia:" - vor dem Link-Namen hinzufügt.
Die Jedermann-Enzyklopädie
Das größte Wiki ist mit Abstand die Wikipedia, die derzeit in ihrer englischen Ausgabe rund 120.000 Artikel zählt. Varianten gibt es in fast allen Sprachen, aktiv sind vor allem die englische, deutsche, französische, polnische, schwedische, dänische, holländische und japanische Wikipedia, und natürlich die Esperanto-Wikipedia, die im Mai 2003 um die 6.500 Artikel verzeichnete. Insgesamt gibt es rund 190.000 Artikel - das nächstgrößte Wiki, das Original-Wiki von Ward Cunningham, wirkt mit an die 25.000 Seiten geradezu mager. Dabei beinhaltet die Wikipedia-Statistik keine Diskussionsseiten, Bilder oder Seiten über die Wikipedia selbst, was allein auf der englischen Wikipedia noch einmal rund 90.000 Seiten ausmacht.
Die Idee, das Wiki-Prinzip auf eine Enzyklopädie anzuwenden, lag mit der zunehmenden Verbreitung von Wikis nicht fern, und es verwundert fast, dass es bis zum Januar 2001 gedauert hat. Wikipedia war zunächst nur ein Experiment, dessen Erfolg alle Beteiligten regelrecht überwältigt hat. Die Idee einer freien Enzyklopädie hat ihre Wurzeln dagegen in einem völlig anderen Projekt, Nupedia.
Das Nupedia-Projekt wurde im März 2000 vom Internet-Unternehmer Jimmy ("Jimbo") Wales gegründet und hatte von Anfang an das Ziel, eine gigantische, freie Enzyklopädie zu schaffen, die Britannica, Encarta & Co. den Garaus machen sollte. Für die Koordination stellte Wales einen Chefredakteur, Larry Sanger, ein.
Von der Bürokratie zur Anarchie
Doch nicht die totale Offenheit sollte zum Erfolg führen, sondern rigorose Qualitätskontrolle durch "Peers", also qualifizierte Experten aus den jeweiligen Fachgebieten. Artikel sollten von motivierten, informierten Freiwilligen stammen, deren Werke einen komplizierten Prozess von Faktenprüfung, Lektorat und Finalisierung überstehen mussten.
Alle Nupedia-Artikel sollten frei verfügbar sein und es auch bleiben. Um das sicherzustellen, wurde die Freie Dokumentationslizenz ( FDL) des GNU-Projekts verwendet. Das GNU-Projekt, verantwortlich für einen großen Teil der existierenden Open-Source-Software, hatte die Lizenz ursprünglich für gedruckte Handbücher entwickelt. Sie erlaubt die Erstellung und Weitergabe von Derivaten (veränderten Kopien), sofern auch diese unter der FDL stehen. Das heißt im Klartext, dass man zwar FDL-Texte beliebig verändern und weitergeben kann - will man sie aber mit anderen Werken kombinieren, muss das gesamte Werk unter der FDL stehen. Das Prinzip ist bekannt: Die beliebte Open-Source-Software-Lizenz GPL funktioniert ähnlich.
In den 3 Jahren seiner Existenz hat Nupedia ca. 30 Artikel produziert - ohne das Wikipedia-Experiment würde das Enzyklopädie-Projekt wohl heute als Beispiel dafür zitiert, warum freie Inhalte keine Zukunft haben. Doch Nupedia scheiterte nicht an mangelnder Bereitschaft - Hunderte von Autoren, zahlreiche davon Wissenschaftler, hatten sich für das Projekt interessiert. "Nupedia ist tot und wird es auch bleiben", befindet Eivind Kjørstad, Informatikstudent aus Norwegen, der sich an dem Projekt beteiligen wollte. "Es gibt kaum einen Anreiz, sich mit der Bürokratie von Nupedia zu befassen, mit den fünf Prüfungsebenen (oder wie viele es auch sein mögen), den endlosen Streitereien, alles für nichts. Die meisten Autoren geben angeekelt auf, bevor sie auch nur halbwegs den 'Prozess' durchlaufen haben."
Im Januar 2001 diskutierte Larry Sanger mit einem Bekannten erstmals die Idee einer Enzyklopädie auf Wiki-Basis. Er war sofort von dem Wiki-Konzept begeistert und zog am 10. Januar 2001 auf der Nupedia-Mailing-Liste die logische Konsequenz: "Let' make a wiki!" Am 15. Januar ging Wikipedia mit der UseMod-Software an den Start - dieser Tag ist seitdem jedes Jahr "Wikipedia Day". Auch alle Wikipedia-Artikel standen von Anfang an unter der GNU FDL.
"Das Ende von CamelCase - hurra!"
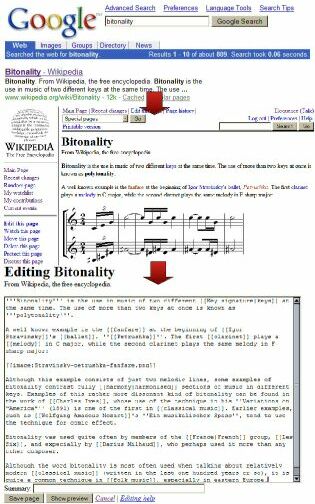
Am 27. Januar schlug Clifford Adams, Hauptautor der UseMod-Software, vor, für Wikipedia eine neue Syntax zum Setzen von Links zu verwenden. Die KamelWorte würden die Zukunft der Enzyklopädie gefährden: Weil es zu viele unterschiedliche Schreibweisen gebe ("DemoCracy", "DemocracY", "DeMocracy" usw.) würden notwendige Links nicht gesetzt. Lesbarer wurden die Texte durch die komische Schreibweise auch nicht. Adams implementierte deshalb speziell für Wikipedia ein Verfahren namens "Free Links" - um einen Link zu setzen, werden um einen Text [[doppelte eckige Klammern]] gesetzt. Das ist zwar schwieriger zu tippen, führt aber zu deutlich lesbareren Artikeln.
Kurzum wurden die Kamele aus der Wikipedia verbannt, doch selbst heute trifft man mitunter noch auf Verweise in CamelCase-Form - ein großes Wiki, das sich einmal für die CamelCase-Syntax entschieden hat, kann praktisch nicht mehr zurück, da eine Konvertierung zu aufwendig ist. Um so wichtiger ist es, sich als Betreiber frühzeitig über den Unterschied im Klaren zu sein. Heute bieten viele Wiki-Engines Free-Link-Funktionalität an.
Wikipedia wuchs schon bald schneller als alle anderen Wikis. Im Februar waren 1.000 Artikel erreicht, im März 2.000, im September 10.000. Ursprüngliche gespeist wurde das Wachstum aus der vorhandenen Nupedia-Community, bald folgten erste Erwähnungen in Weblogs, schließlich Online-Magazine, im September 2001 die New York Times.
Von Grund auf neu
Schon bald entpuppte sich die UseMod-Software als zu beschränkt. Der Kölner Biologie-Student Magnus Manske entwickelte daraufhin mit Hilfe der Skriptsprache PHP und der Datenbank MySQL eine neue Software, die viele Wikipedia-Kinderkrankheiten ausmerzte. Diskussionsseiten und Seiten über Wikipedia wurden von Artikelseiten streng getrennt. Das Benutzerinterface wurde in viele Sprachen übersetzt. Unterstützung für das komfortable Hochladen von Bilddateien wurde hinzugefügt. Neue Schutzmechanismen kamen hinzu, Administratoren wurden ernannt, die Seiten löschen und Benutzer wegen Vandalismus verbannen konnten.
Doch die vielen neuen Funktionen hatten ihren Preis. Schon bald ging die Performance der Wikipedia in die Knie, und lange Wartezeiten beim Laden und Bearbeiten von Artikeln waren die Regel. Wieder einmal wurde die Software neu geschrieben, diesmal von dem Kalifornier Lee Daniel Crocker. Diese neue Software, bekannt als Wikipedia "Phase III" und wie alle vorherigen Versionen Open Source, ist seit Juli 2002 in Gebrauch und wird nun auch von einigen Spin-Off-Projekten verwendet (dazu mehr in Teil 2).
Eine wesentliche neue Funktion, die Wikipedia anderen Wikis voraus hat, sind sogenannte Beobachtungslisten: Alle in diese Liste eingetragenen Artikel lassen sich gesondert von den "Recent Changes" über einen längeren Zeitraum überwachen. Wer also viel Zeit in einen umfangreichen Artikel investiert hat, muss nicht ständig auf die Liste aller Änderungen schielen - ein regelmäßiger Blick auf die Beobachtungsliste genügt, und unerwünschte oder unpassende Änderungen durch Dritte können verbessert, gelöscht oder integriert werden.
Kampf den Wiki-Hooligans
Seitens der Administration wurde stets auf eine möglichst transparente Vorgehensweise geachtet. Soll eine Seite beispielsweise gelöscht werden, muss sie - sofern es sich nicht um eine offensichtliche Nonsens-Seite handelt - auf einer Spezialseite namens "Votes for deletion" (auf der deutschen Wikipedia: "Seiten, die gelöscht werden sollen") eingetragen werden. Dort bleibt sie eine Weile stehen, und sofern niemand Einspruch erhobt, darf ein Sysop sie entfernen. Gibt es dagegen Widerspruch, gilt das Konsens-Prinzip: Entscheidungen müssen wenn irgend möglich einvernehmlich gefällt werden. Kontroverse Inhalte werden deshalb eher verschoben, umbenannt oder nachbearbeitet als gelöscht.
Bei der Verbannung von Benutzern gelten ähnlich strenge Regeln. Sofort darf ein Nutzer nur in Fällen von offensichtlichem Vandalismus verbannt werden, ansonsten ist eine Diskussion mit Wiki-Eigentümer Jimbo Wales höchstpersönlich erforderlich. In 2 Jahren hat er gerade mal eine Handvoll registrierter Nutzer verbannt. Dabei macht die einfache Neuanmeldung eine effektive Durchsetzung der Regeln ohnehin schwer - bei der Registrierung findet keinerlei Identitätsprüfung statt. Deshalb kehren Regelverletzer häufig unter neuem Namen zurück.
Trotzdem ist die Diskussionsatmosphäre erstaunlich zivilisiert. In der Regel konzentrieren sich Gespräche tatsächlich darauf, wie ein Artikel verbessert werden kann. Natürlich gibt es auch "Flamewars" (Internet-Slang für hitzige Diskussionen), aber meist ruft ein Außenseiter die Teilnehmer rechtzeitig zur Ordnung. Wikipedia ist schließlich nicht primär eine Diskussionsplattform, sondern eine Enzyklopädie. "Tragt das woanders aus", lautet also die häufige Reaktion auf Entgleisungen. Kommt es zu Streitigkeiten, steigt auch das Risiko von Bearbeitungskonflikten - wenn ein Nutzer einen Artikel verändert hat, während ein anderer noch eine ältere Version bearbeitet, muss derjenige, der als letztes speichert, beide Versionen mühselig miteinander verknüpfen.
Auch aus anderen Gründen zahlt sich unfreundliches Verhalten auf Wikipedia nicht aus: Man erlangt schnell eine entsprechende Reputation und muss damit rechnen, verbannt zu werden - zumindest aber damit, dass andere Nutzer die eigenen Bearbeitungen besonders kritisch beäugen. Und der gleiche Nutzer, den man gerade beleidigt hat, ist vielleicht schon beim nächsten Artikel ein potenzieller Alliierter. Und damit es auch der letzte versteht, gibt es natürlich auch Verhaltensregeln für Wikipedianer - bekannt als Wikipetiquette.
Relevante Links:
Literatur:
Cunningham, Ward und Leuf, Bo: The Wiki Way. Collaboration and Sharing on the Internet. Addison-Wesley (2001). ISBN 020171499X.
Das Wiki-Prinzip
Tanz der Gehirne: Teil 2
Quantitativ kann sich Wikipedia durchaus mit bekannten Nachschlagewerken messen. Doch das Vorurteil, ohne jegliche redaktionelle Kontrolle und mit teilweise völlig anonymen Beiträgen könne ein Wiki nie hochwertige Informationen liefern, liegt nahe. Verdient Wikipedia wirklich den Namen Enzyklopädie? Gibt es bereits Bereiche, in denen das offene Projekt die gedruckten oder gepressten Werke übertrumpft? Die Antworten verraten mehr über unsere Kultur, als wir vielleicht glauben.
Im Größenvergleich mit bekannten Multimedia-Lexika steht Wikipedia bereits gut da: Die rund 120.000 Artikel der englischen Ausgabe stehen etwa 85.000 Artikeln in der 2002er Encyclopaedia Britannica, 60.000 Artikeln in Microsofts Encarta Deluxe 2002 und 39.200 Artikeln in der Grolier-Enzyklopädie gegenüber. Die 24-bändige Brockhaus-Enzyklopädie wuchtet dagegen rund 260.000 Stichwörter.
Viele Wikipedia-Artikel enthalten statistische Daten aus offiziellen Werken. So gibt es etwa 36.000 Einträge über US-Dörfer und Städte, die automatisch aus den US-Volkszählungsdaten generiert wurden (Beispiel: Pownal, Vermont). Viele davon wurden zwar nachträglich um interessante Informationen ergänzt, doch nicht jedes Kuhdorf hat auch einen Wikipedia-Benutzer, der davon erzählen könnte. In der englischen Wikipedia findet man auch Informationen über die deutschen Landkreise (Beispiel: Oberbergischer Kreis), über finnische Provinzen, über japanische Präfekturen usw.
Auch Listen sind in Wikipedia zahlreich vertreten - Listen von Städten, Restaurants, Taschenrechnern, Genkrankheiten, Dämonen, fiktiven Katzen, Gewerkschaften, Bürgerkriegen, Entführungen, Militärbasen, verbotenen Büchern, Indie-Plattenlabels, Schacheröffnungen und Episoden der Serie "Buffy: Der Vampirkiller", um nur einige zu nennen.
Die Artikel in Wikipedia sind über zahlreiche Ordnungsschemata kategorisiert. Auf der Hauptseite finden sich verschiedene Oberkategorien, die man ähnlich einem Web-Katalog wie Yahoo! durchblättern kann. Daneben gibt es einige mehr oder weniger gepflegte alternativen Kategorisierungen, wie z.B. das Schema der Library of Congress. Für die Moderne gibt es für jede Jahreszahl einen eigenen Artikel, in dem sich wiederum Verweise auf relevante Ereignisse befinden. Wweniger gut dokumentierte Zeiten wie das finstere Mittelalter sind dagegen in Jahrzehnte unterteilt. Ein alphabetisches Durchblättern ist natürlich ebenfalls möglich, und auch eine Zufallsanzeige fehlt nicht.
In einem Wiki sind Verweise schnell gesetzt, deshalb befinden sich innerhalb jedes Artikels zahlreiche Links - weitaus mehr als selbst in Multimedia-Enzyklopädien wie Encarta. Existiert der Artikel noch nicht, ist der Link rot, und der Text kann durch Anklicken angelegt werden. Weil manche Artikel unter verschiedenen Namen auftreten können, gibt es sogenannte Weiterleitungen. Folgt man z.B. einem Link auf Chomsky, wird man automatisch weitergeleitet auf den Artikel über Noam Chomsky. Die hohe Zahl von Links führt zum Symptom des Sich-Verlierens, das viele Wikiholiker beschreiben.
Bei der Suchfunktion haben CD-ROM-Enzyklopädien derzeit noch die Nase vorn: Sie verfügen meist über komplexe Abfragemasken und einen schnellen Index. Die Suchfunktion der englischen Wikipedia hat dagegen häufig mit Performance-Problemen zu kämpfen und wird zeitweise gänzlich deaktiviert. Benutzer werden dann an Google verwiesen, wo eine Suche mit einer speziellen Einschränkung auf Wikipedia-Seiten durchgeführt werden kann. Leider indexiert Google jedoch nicht alle Artikel und ist nur begrenzt aktuell. Bei den kleineren fremdsprachigen Wikipedias kann stets die interne Volltextsuche verwendet werden, die immerhin Boolesche Verknüpfungen (AND, OR, AND NOT) unterstützt und gefundene Stichwörter farbig im Kontext hervorhebt.
Fehlerteufel
Wer ein wenig in Wikipedia blättert, stößt hier und da auf störende Kleinigkeiten: ein sinnloser Satz, redundanter Text, eine unglaubhafte Behauptung ohne Quellenangabe, eine stilistisch unpassende Passage in einem langen Text oder gar amateurhaft wirkende Einschübe wie "(stimmt das wirklich?)". Um Wikipedianer zu werden, muss man keinen Kurs belegen: Der Lerneffekt soll langfristig allein durch die Partizipation entstehen. Und selbst wenn Dutzende Benutzer am gleichen Text schreiben, können solche Probleme leicht übersehen werden.
Die schiere Menge an Inhalten zu jedem erdenklichen Thema ist für die meisten Besucher überwältigend, doch von einer einheitlichen Qualität kann keine Rede sein. Das veranlasst viele Journalisten, die über Wikipedia berichten, zu einem einfachen Schnellurteil: ein interessantes Projekt, aber noch lange keine Konkurrenz zu klassischen Nachschlagewerken.
|
Doch dieses Urteil greift zu kurz. Wikipedia befindet sich eben in einem ständigen Fluss - ein Artikel, der gerade noch völlig in Ordnung war, kann Minuten später von einem anonymen Nutzer komplett umgearbeitet worden sein. Vandalismus wird, wie in Teil 1 beschrieben, meist früh erkannt und rückgängig gemacht. Auch subtile Änderungen können mittels der Differenz-Funktion ihren Autoren zugeordnet und korrigiert werden. Werbe-Einträge werden nicht toleriert und umgehend gelöscht. Entgegen der Intuition ist reine Bosheit das geringste Problem in Wikis - Unwissenheit, Unfähigkeit, ideologisches Denken oder einfache Nachlässigkeit sind problematischer.
Wurde ein Artikel sehr häufig editiert, ist in der Tendenz festzustellen, dass die Fakten besser geprüft wurden als in anderen Texten, aber Vorsicht ist geboten: Gelegentlich kommt es zu sogenannten "Edit-Kriegen", bei denen zwei Benutzer um die Version des Textes streiten und versuchen, ihre Version durch mehrfaches Speichern durchzusetzen. Solches Verhalten ist natürlich verpönt, und wenn ein Sysop davon Kenntnis nimmt, ist er aufgerufen, zu einer Schlichtung beizutragen. Zu diesem Zweck kann er die Seite vorübergehend schützen, d.h., sie ist nicht mehr editierbar, bis die Nutzer sich geeinigt haben. Nur unbeteiligte Dritte dürfen als Schlichter fungieren, denn Sysops agieren innerhalb von Wikipedia nur als Repräsentanten der Benutzergemeinde und haben relativ wenig Entscheidungsfreiraum.
Ein Artikel mit vielen Revisionen kann also einfach ein besonders heiß umkämpfter Text über ein komplexes Thema sein. Ein Beispiel dafür ist der englische Wikipedia-Text über Richard Wagner, der mit über 250 Revisionen zu den am meisten editierten Artikeln überhaupt gehört. Ein Nutzer war der Meinung, dieser Text sollte keine Informationen über Wagners Antisemitismus enthalten - man dürfe einen Menschen, der so wundervolle Kunstwerke geschaffen hat, nicht durch solch unwichtige Details über "Jugendsünden" schmähen. Statt dessen sollte die Angelegenheit, wenn überhaupt, in einem separaten Artikel zusammengefasst werden. Es folgte ein langwieriger Edit-Krieg, der natürlich viele Nutzer abschreckte und dazu führte, dass die oben erwähnten Schlichtungsprozeduren eingeführt wurden. Letztlich wurde der Nutzer wegen anderer Verstöße gegen die Wiki-Etikette verbannt, der Text über Wagner behandelt die Problematik des Antisemitismus erwartungsgemäß ausführlich.
Das höchste Gebot
Wer Wikipedia nicht kennt, mag von solchen Extrembeispielen schockiert sein und erwarten, dass das Projekt voller ideologischer Texte ist, die nur eine Meinung vertreten. Doch davon kann keine Rede sein. Dafür sorgt das philosophische Vermächtnis von Larry Sanger, dem Projektmitbegründer, der im März 2002 seinen Posten als "Herausgeber" aufgab. Sanger entwickelte die Regel des "neutralen Standpunkts" bzw. "neutral point of view", unter Wikipedianern kurz als NPOV bekannt. In der klassischen Wiki-Philosophie gibt es keine Regeln, die eingehalten werden müssen. "Ignore all rules", heißt es deshalb auch noch auf manchen Wikipedia-Seiten. Doch von diesem Grundsatz ist das Projekt längst abgerückt, und die NPOV-Doktrin ist unantastbar. Wer sie wiederholt verletzt, muss damit rechnen, verbannt zu werden: Er kann dann zwar noch Artikel lesen, aber nicht mehr bearbeiten.
NPOV heißt nicht, dass die Autoren selbst keine Meinung haben dürfen. Sie dürfen sie nur nicht fälschlich als die einzig vorhandene oder gar die einzig richtige Meinung repräsentieren. "Ein Artikel sollte nicht behaupten, dass Großunternehmer Verbrecher sind, auch wenn der Autor dies glaubt. Statt dessen sollte er darauf hinweisen, dass einige Menschen dies glauben, was ihre Gründe sind und was die andere Seite denkt", erklärt Wikipedia-Gründer Jimbo Wales. Das gleiche gilt für jeden anderen Standpunkt. Sofern sich aus glaubhaften Quellen belegen lässt, dass eine relevante Zahl von Menschen den Standpunkt vertritt, kann er in einem Artikel zitiert werden. Ein Wikipedia-Artikel wird deshalb selten eindeutige Schlussfolgerungen ziehen. Statt dessen werden meist verschiedene alternative Sichtweisen präsentiert. Stellt sich natürlich in der Diskussion heraus, dass eine bestimmte Argumentation unlogisch oder fehlerhaft ist, so kann dies auch vermerkt werden. Eindeutige Falschinformationen müssen nicht der Neutralität halber weiterverbreitet werden.
Auch Extremismus findet aufgrund der NPOV-Logik nicht automatisch seinen Weg in Artikel. Das scheitert meist schon an der mangelnden Intelligenz der Protagonisten: Nur wenige Rassisten sind in der Lage, ihren Standpunkt in einer NPOV-konformen Weise zu formulieren. Die NPOV-Doktrin besagt weiterhin, dass die Zahl und Reputation derjenigen, die einen Standpunkt vertreten, dafür entscheidend ist, wo dieser Standpunkt wiedergegeben wird. So wurden zum Beispiel die Argumente der Holocaust-Leugner in einen eigenen Artikel ausgelagert. Trotzdem entspricht natürlich auch dieser Artikel dem NPOV und präsentiert Argumente beider Seiten.
Die NPOV-Philosophie ist nichts grundsätzlich Neues - Journalisten folgen ähnlichen Richtlinien, und auch konkurrierende Enzyklopädien bemühen sich um Neutralität. Doch so konsequent verfolgt wie bei Wikipedia wird sie fast nirgendwo. Der Versuch, Argumente aller Seiten zu präsentieren, erfordert bei komplexen Fragen neue Herangehensweisen. In der aktuellen Revision des Artikels über den amerikanischen Drogenkrieg findet sich z.B. ein regelrechter Argumentbaum, der Pro- und Contra-Positionen in Bezug aufeinander wiedergibt. Wer häufig an Diskussionen über bestimmte Themen teilnimmt, findet hier wertvolle Schützenhilfe. Für eine Enzyklopädie ist diese Art der Auseinandersetzung aber außergewöhnlich, und manchen wird sie stilistisch unangemessen vorkommen.
NPOV wirft auch philosophische Fragen auf. Kann man es z.B. jugendlichen Lesern zumuten, offen mit bestimmten Argumenten konfrontiert zu werden oder muss eine Enzyklopädie moralisch Stellung beziehen? Landet Wikipedia womöglich in Deutschland auf dem geheimen Index jugendgefährdender Schriften, weil blasphemischen oder sexuell freizügigen Ansichten nicht zur Genüge Einhalt geboten wird? Während die Amerikaner ihre verfassungsmäßig geschützte Meinungsfreiheit genießen, müssen die deutschen Wikipedianer hoffen, dass nicht der ein oder andere Regierungspräsident von dem Projekt Kenntnis nimmt ..
Quellensuche
Klassische Enzyklopädien verzichten häufig auf genaue Quellenangaben. Bibliographien sind zwar bei größeren Texten meist vorhanden, doch die hohe Reputation einer Encyclopaedia Britannica erlaubt es dem Leser, sie als Sekundärquelle zu zitieren. Wikipedia kann in der jetzigen Form diese Reputation kaum erreichen und muss deshalb Quellenbelege für wesentliche Faktenaussagen liefern. Verweise auf gedruckte Quellen sind in der Praxis eher die Ausnahme, die meisten Wikipedianer nutzen das Web zu Recherchezwecken. Das muss nicht schlecht sein, denn zahlreiche hochwertige Publikationen sind im Volltext im Web zu finden. So finden sich in manchem Artikel (Beispiel: Sex Education ) Links direkt auf Studien im "British Medical Journal", im "Cancer Journal" oder anderen renommierten Fachzeitschriften.
Die zunehmende Verfügbarkeit wissenschaftlicher Arbeiten im Netz ( Free Online Scholarship) wird diesen Trend sicher noch verstärken. Besonders geeignet für Enzyklopädie-Artikel sind dabei sogenannte Meta-Analysen, die Studien zu einer Fragestellung zusammenfassen und auch methodologisch bewerten. Der NPOV stellt sicher, dass bei kontroversen Themen wie Homöopathie nicht einseitig Studien ausgewählt werden dürfen, die eine bestimmte Sichtweise unterstützen.
|
Zweifellos enthält Wikipedia mehr ausgewählte Weblinks als jede andere Enzyklopädie. Während Encarta & Co. meist auf komplette Sites zu einem bestimmten Thema verweisen, zeigen Wikipedia-Artikel auch auf Online-Papers, News-Artikel, Weblog-Einträge, Usenet-Postings usw. Erscheint ein Link nicht glaubhaft, wird er entfernt, zeigt er auf eine ideologisch motivierte Website, wird häufig ein entsprechender Hinweis hinzugefügt (Beispiel: Global Warming] - die über 20 Links sind in 6 Kategorien aufgeteilt).
An Fotos und Illustrationen mangelt es Wikipedia ebenfalls nicht. Viele Wikipedianer gehen selbst auf Motivsuche und stellen ihre Bilder unter den Bedingungen der FDL oder völlig lizenzfrei zur Verfügung. Auch Karten, Diagramme und andere Illustrationen werden schon einmal ad hoc erstellt. Daneben gibt es noch Bilder und Fotos, die nicht urheberrechtlich geschützt sind. Das sind zum einen Gemälde oder Veröffentlichungen, deren Schutz abgelaufen ist (70 Jahre nach dem Tod des Autors). Zum anderen gibt es aber auch Bildersammlungen, die frei zur Verfügung gestellt wurden - entweder, weil die Urheber es so wollten oder, was bedeutender ist, weil sie im Auftrag der amerikanischen Regierung erstellt wurden. Veröffentlichungen der Regierung müssen in den USA der Allgemeinheit zur Verfügung stehen, so dass die riesigen Archive der NASA, der Forst- und Landwirtschaftsbehörden, des Militärs usw. frei nutzbar sind. Dabei handelt es sich oftmals um hochprofessionelle Fotografien. Um die Recherche zu vereinfachen, gibt es eine Liste der entsprechenden Archive.
Ähnliches gilt für Deutschland nicht, und auch sonst bereitet das Urheberrecht Schwierigkeiten. Viele Museen haben zum Beispiel strikte Richtlinien gegen das Fotografieren bestimmter oder gar aller Ausstellungsstücke und bestehen auf der Nutzung eines kostenpflichtigen Reproduktions-Services, oft in Verbindung mit einem stark eingeschränkten Nutzungsabkommen. Ob das bei Kunstwerken, deren Inhalt längst nicht mehr geschützt ist, überhaupt legal ist, sei dahingestellt. Praktiziert wird es dennoch, teilweise mit der Rechtfertigung, die Digitalisierung selbst stelle einen Schöpfungsakt dar und sei deshalb schützenswert. Auf politische Reformen in diesen Bereich zu hoffen heißt, den verantwortlichen Politikern einen hohen Grad von Intelligenz, Wissen und Integrität zuzuschreiben.
Professoren und Teenager
Bei Wikipedia kann jeder mitmachen, doch eine offene Enzyklopädie zieht vorwiegend Menschen mit akademischem Hintergrund an. Informatiker sind zahlreich vertreten, was wohl damit zusammenhängt, dass Wikipedia bereits eine hohe Penetration in Internetmedien wie Weblogs und Diskussionsforen hat. Doch Biologen, Mathematiker, Historiker, Juristen, Musiker, Linguisten und Experten oder Amateure aus zahllosen anderen Disziplinen sind ebenfalls an dem Projekt beteiligt. An fachlich qualifizierten Mitarbeitern herrscht bei den über 10.000 registrierten Nutzern kein Mangel, viele davon könnten wohl ohne Weiteres einen Job bei der Encarta- oder Britannica-Redaktion bekommen.
Was motiviert diese Menschen? Menschen wie Axel Boldt, Mathematikprofessor an der Metropolitan State University in Saint Paul, Minnesota und einer der aktivsten Wikipedianer. Oder Jani Melik, CAD-Designer und abgebrochener Physik- und Astronomie-Student aus Celje in Slowenien. David Wheeler, Software-Designer und Buchautor aus Virginia, USA, und Verfasser mehrerer Studien über Open-Source-Software. Oder James Duffy, Historiker und Politologe aus dem irischen Dublin. "Es gibt verdammt viele intelligente Leute auf Wikipedia, und ich empfinde es als intellektuelle Herausforderung, dabei zu sein", meint Duffy, der in einem Monat über 400 Euro an die irische Telefongesellschaft für seinen "Wikiholismus" bezahlt hat und auch schon mal beim Buckingham-Palast anruft, um dort zu erfahren, wie die stilistisch korrekte Titulierung der Mitglieder des britischen Königshauses lautet. "Ein paar von uns haben über einen Monat daran gearbeitet, und heute gehören die Informationen über die Royals zu den akkuratesten im Internet."
Dabei ist Ruhm und Ehre zumindest für Duffy nur eine sekundäre Motivation. "Zu wissen, was Du geleistet hast, ist oft wichtiger, als dafür gelobt zu werden. Als aber zum Beispiel mein Artikel über das Irische Parlamentgebäude auf der Seite der besten Artikel eingetragen wurde, war ich hocherfreut, insbesondere, da ich auch die Fotos dafür gemacht hatte." Immerhin wird in der Artikelhistorie der Beitrag jedes Autors für die Ewigkeit festgehalten.
Unter den Wikipedianern gibt es auch Jugendliche wie den 14jährigen Daniel Ehrenberg aus Rochester, New York, Linux-Benutzer und Esperanto-Fan, der über fast alle Themenbereiche schreibt und vergeblich versucht, seine Klassenkameraden von dem Projekt zu begeistern. Es gibt Couch-Potatoes, die alles über ihre Lieblings-Fernsehserien sammeln. Rentner, die ihre besten Fotos scannen und in passenden Wikipedia-Artikeln veröffentlichen. Und natürlich auch viele, die aus Eitelkeit einen Enzyklopädie-Artikel über ihr eigenes Projekt schreiben möchten, sei es eine Band, ein Online-Rollenspiel oder eine Kunstausstellung. In diesem Fall wird häufig ein sogenannter "Google-Test" durchgeführt - lassen sich die Informationen nicht aus glaubwürdigen Quellen nachvollziehen, werden sie zusammengestutzt oder gelöscht.
Auch viele religiöse Menschen arbeiten an der Enzyklopädie mit. Die Heiligen des Katholizismus werden von entsprechenden Anhängern ähnlich eifrig eingetragen wie die verschiedenen Figuren aus dem Star-Trek-Universum von dessen Fans. Dass dabei der NPOV mitunter zu kurz kommt, versteht sich, insbesondere wenn gleich ganze Artikel aus der 1908er Catholic Encyclopedia übernommen werden, die frei verfügbar ist.
Qualitätsvergleich
Trotz erwiesener guter Absichten der meisten Teilnehmer kommt man bei einer Beurteilung von Wikipedia um einen direkten Vergleich nicht herum. Will man die Qualität der Wikipedia-Artikel ernsthaft mit der anderer Enzyklopädien vergleichen, muss man verschiedene Fragen stellen:
Als Referenz-Enzyklopädie wird im folgenden die Microsoft Encarta Enzyklopädie Professional 2003 (deutsche Version) verwendet. Zunächst führen wir eine zufällige Auswahl von 10 Artikeln aus der englischen Wikipedia durch und vergleichen diese mit entsprechenden Pendants in der Encarta. Danach folgt eine entsprechende Selektion von fünf Encarta-Artikeln.
Zufallsauswahl: Zehnmal Wikipedia
Treffenderweise ist der erste Wikipedia-Zufallstreffer ein Artikel über die Encyclopedia Galactica. Wir lernen in zwei Absätzen, dass es sich hierbei um eine fiktive Enzyklopädie galaktischer Zivilisationen handelt, eine Idee, die unter anderem in Isaac Asimovs "Foundation"-Serie verwendet wird. Der Artikel ist sprachlich korrekt und wird durch einen Link auf ein gleichnamiges Web-Projekt vervollständigt, das sich offenbar an Science-Fiction-Veröffentlichungen anlehnt. Eine Beschreibung des Links wäre hilfreich. Ein Gegenstück in Microsofts Encarta existiert erwartungsgemäß nicht, auch der Encarta-Artikel über Asimov erwähnt das Konzept mit keinem Wort.
Der zweite Wikipedia-Zufallsartikel ist California State University San Bernadino. Auch dieser Artikel ist knapp, nennt das Gründungsjahr, die Zahl der Studenten im Jahr 2003, das Fächerangebot und einige Details über das Sportprogramm. Auch in diesem Fall gibt es einen Link, diesmal auf die offizielle Website. Kein Äquivalent in Microsofts Encarta. Immerhin gibt es zwei Absätze über eine andere "State University" in Kalifornien, die San Francisco State University. Dieser Artikel enthält weniger Detailinformationen, verrät uns aber etwas über die erwerbbaren Abschlüsse (Bakkalaureus, Magister, Magister Artium).
|
Das Wikipedia-Gegenstück hierzu, San Francisco State University, ist dagegen derzeit mit zwei Sätzen und einem Weblink noch recht erbärmlich. Wie kam es dazu? Ein Blick in die Artikelhistorie verrät, dass an Stelle des Artikels ursprünglich am 22. November 2002 ein Nonsens-Text angelegt wurde. Anstatt den Text zu löschen, schrieb ein anderer Mitarbeiter schnell wenigstens zwei Sätze hinein und machte den Text so zu einem sogenannten "Stub" (Stumpf), den andere um Details erweitern sollen.
Unser dritter Zufallstreffer ist ein Text über Henry Ford II., den Enkel von Henry Ford. Mit 3682 Zeichen ist er unser bisher umfangreichster Text. Der Text beschreibt wie Ford die Firma seines früh verstorbenen Vaters Edsel Ford zunächst nicht übernehmen konnte, weil er im II. Weltkrieg bei der Marine war - so musste Großvater Ford noch einmal ran. Erst 1945 durfte der Enkel ans Ruder der Firma, die kurzzeitig ins Straucheln geraten war. Wir erfahren von Fords aggressivem Management und von seinen Personalentscheidungen.
Der Artikel ist sprachlich korrekt, könnte aber durch ein paar Zwischenüberschriften aufgelockert werden. Zumindest ein Suchmaschinen-Test belegt, dass es sich um Originalmaterial handelt, und der Text enthält zahlreiche Querverweise. Ein stichprobenartiger Google-Check bestätigt auch die im Artikel gemachten Faktenangeben, der Text selbst enthält keine Quellenangaben. Geschrieben wurde er von einem einzigen Wikipedianer, "Hephaestos", von dem wir nicht viel erfahren, außer, dass für ihn Wikipedia und Zigaretten zum Frühstücksritual gehören und dass er Spaß am Korrekturlesen hat - aber immerhin nennt er eine Email-Adresse, unter der man ihn kontaktieren kann.
Das Encarta-Äquivalent besteht aus zwei Sätzen. Statt Geburtsdaten gibt es nur Jahreszahlen. Der zweite Satz lautet: "Von 1945 bis 1960 war er Präsident, dann Verwaltungsratsvorsitzender der Ford Motor Company." Wir erfahren nichts darüber, was "dann" heißt, d.h. wie lange und in welchen Positionen Ford nach seiner Firmenpräsidentschaft dort tätig war. Quelleninformationen, Bilder, Links, Autoreninformationen - null.
Als nächstes geht es nach Ashfield, Massachusetts, einer amerikanischen Kleinstadt. Der Artikel gehört zu den erwähnten aus den US-Volkszählungsdaten generierten Texten. Neben geographischen und demographischen Daten enthält der Artikel keine weiteren Informationen und wurde auch nicht weiter editiert - kein Wunder, die Stadt hat 1800 Einwohner. Eine Encarta-Suche erübrigt sich fast - ein Gegenstück existiert nicht, was verzeihlich ist.
Der Wikipedia-Text über Chris Marker, einen französischen Dokumentarfilmer, ist drei Sätze kurz und explizit als "Stub" gekennzeichnet. Er enthält biographische Daten und einen Verweis auf den Film "La Jetée", über den es ebenfalls einen Artikel gibt. Hier hat Encarta die Nase vorn: Mit rund 1400 Zeichen ist der Text deutlich ausführlicher und referenziert Markers bedeutendste Werke. Er erwähnt Markers "radikale politische Ansichten", nennt diese aber nicht, und bezeichnet Markers Film "A.K." als "faszinierend" - die Meinung des Autors? Für Wikipedia wäre das "POV", das Gegenteil von NPOV, und damit inakzeptabel. Der Artikel enthält drei Literaturangaben.
Über das Heine-Borel-Theorem erfahren wir in Wikipedia, dass es ein Satz der mathematischen Analysis ist, der besagt, dass eine Untermenge der realen Zahlen R kompakt ist, wenn sie abgeschlossen und beschränkt ist. Wir lernen auch, dass der Satz auf metrische Räume anwendbar ist, aber einen mathematischen Beweis finden wir nicht. Ein Blick auf die Diskussionsseite zeigt, dass der Mathematiker Axel Boldt einen vorhandenen Beweis entfernt hat, weil er teilweise fehlerhaft war. Ein Encarta-Artikel über den Satz existiert nicht.
Es folgt mit dem Text über das Buch I, Claudius von Robert Graves ein weiterer Abstecher in die Welt der Fantasie. Wir erfahren nur, dass es vom Leben des römischen Kaisers Claudius handelt, dafür gibt es geschichtliche Informationen über die Verfilmung des Buches - einen ersten Versuch, der wegen eines Unfalls fehlgeschlagen ist, und schließlich eine erfolgreiche Produktion der BBC. Der Text enthält eine Titelgrafik des Buches, die jedoch von schlechter technischer Qualität ist. Einen Encarta-Artikel über das Buch gibt es nicht, auch der Encarta-Artikel über Robert Graves enthält keine Einzelheiten darüber.
Der Zufall führt uns nun zum Text über Hybridfahrzeuge, die mit Verbrennungsmotoren und Batterien funktionieren. Der Artikel spricht von "great advantages", was etwas überschwenglich klingt, und zählt diese angeblichen Vorteile auf. Der Text verweist schließlich darauf, dass das erste Hybridfahrzeug 1928 von Ferdinand Porsche entwickelt wurde, dass aber die ersten in Masse produzierten Modelle erst in diesem Jahrhundert von Firmen wie Toyota und Honda entwickelt wurden. Encarta hat keinen eigenen Artikel über Hybridfahrzeuge. Der Artikel "Elektroantrieb" enthält dafür zwei Absätze über Hybridmotoren, jedoch keine Informationen über ihren Einsatz. Der Text ist immerhin mehr als doppelt so lang als sein Wikipedia-Äquivalent, besser strukturiert und illustriert.
Über das Programm VariCAD für die Erstellung von mechanischen Modellen im Computer erfahren wir in vier Sätzen nur recht wenig, aber ein Link auf die Programm-Homepage ist vorhanden. Artikel über Computerprogramme findet man in Encarta kaum, selbst über das Profi-Tool AutoCAD gibt es keinen Text, über VariCAD natürlich auch nicht. Wikipedia enthält dagegen über praktisch jedes Programm im Masseneinsatz und über zahlreiche Open-Source-Anwendungen eigene Artikel.
Auch der Text über Xanadu, die opulente Sommer-Hauptstadt des Mongolen Kublai Khan, ist nur sehr knapp. Er zitiert den Besuch Xanadus durch Marco Polo und ein Gedicht von Samuel Taylor Coleridge, das Xanadu zur beliebten Metapher für Dekadenz werden ließ. Ein Hinweis auf Citizen Kane wäre nett gewesen. Einen kleinen Tippfehler habe ich korrigiert. Immerhin gibt es einen Link auf den knappen Artikel über "Project Xanadu", Ted Nelsons 1960 gestartetes Hypertext-Projekt. Nach der Encyclopaedia Galactica endet unser Zufallsvergleich also mit einem Hinweis auf die Idee eines massiven, bidirektionalen, offen editierbaren globalen Informationsnetzes. Viele der Xanadu-Ideen wie Backlinks und Versioning finden sich in Wikis wieder.
Zufallsauswahl: Fünfmal Microsoft
Microsofts Encarta hat keine Zufallsfunktion, also musste ich die wissenschaftliche Methode des "10 Sekunden mit geschlossenen Augen wie verrückt am Scrollbalken drehen" einsetzen. Der erste so gefundene Text ist der Artikel über Robert Mugabe, Premierminister und Staatspräsident von Zimbabwe. Sowohl der Encarta-Artikel als auch der Wikipedia-Text sind ausführlich: etwa 10500 Zeichen bei Wikipedia, etwa 7500 bei Encarta. Doch angesichts Mugabes Politik der Enteignungen stellt sich die Frage nach der Wahrung der Neutralität: Welcher Artikel ist einseitiger? Angesichts der Länge des Textes können wir hier außerdem erstmals gut prüfen, ob kollaborativ verfasste Wikipedia-Texte auch lesbar sind.
Der Wikipedia-Text behandelt ausführlich die politische Verfolgung von Mugabes früheren Koalitionspartnern durch die als "berüchtigt" bezeichnete Fünfte Brigade; der Encarta-Text ignoriert diesen Abschnitt weitgehend und spricht nur davon, dass eine "Einparteienherrschaft" errichtet wurde. Wikipedia schreibt von Gesundheitsreformen und Bildungsprogrammen für die schwarze Bevölkerung, Encarta berichtet kaum über Mugabes eigentliche Politik und mehr über seine langfristige Machtkonsolidierung und Änderungen des politischen Systems. Der Wikipedia-Text behandelt Mugabes Verfolgung von Homosexuellen und seine Intervention im kongolesischen Bürgerkrieg, der Encarta-Text berichtet nicht darüber. Beide Texte beschreiben die Kontroverse um die letzte Präsidentschaftswahl im März 2002 und sind damit hinreichend aktuell.
Der Wikipedia-Abschnitt über Mugabes "Landreformen" diskutiert die Argumente der Befürworter und Gegner ausführlich und erklärt, dass unter anderem die Zersplitterung vorheriger Großfarmen und sinnlose Zerstörungen von Maschinen, die vorher Weißen gehörten, zu Produktivitätsverlusten führten. Der Encarta-Text enthält dafür mehr Zahlen über die Enteignungen. Wikipedia fasst kurz zusammen, dass Zimbabwe vorher eine Kolonialmacht namens "Rhodesien" war, benannt nach dem Finanzmagnaten Cecil Rhodes, dessen Firma das Land im 19. Jahrhundert übernommen hatte. Der Encarta-Artikel erwähnt dies nicht, man findet entsprechende Informationen allerdings vergraben im Artikel über Zimbabwe.
Insgesamt wirkt der Encarta-Artikel strukturlos und trocken, eine reine Auflistung von Zahlen und Fakten, die langen Absätze sind noch nicht einmal aufgelockert durch Überschriften. Ein einziges sprödes Schwarzweiß-Bild illustriert den Text. Weblinks gibt es nicht, dafür aber einen Verweis auf eine Encarta-Eigenheit, das "Historama", in dem man sich die Geschichte Zimbabwes als Zeitlinie anschauen kann. Der Wikipedia-Artikel enthält mehrere Überschriften; ein paar kleinere stilistische Fehler und ein mörderlanger Absatz fallen störend auf. Fünf Weblinks auf Artikel über Mugabes Politik ergänzen den Text.
Ein Blick auf die Diskussionsseite und in die Edit-Geschichte zeigt, dass es bereits lange Kontroversen um die NPOV-Darstellung von Mugabes Politik gab, die derzeitige Version stellt einen seit etwa einem Monat stabilen Kompromiss dar. Angesichts der positiven Entwicklung des Artikels zeichnet sich hier langfristig ein deutlich besserer Text als im Microsoft-Kompendium ab.
|
Als nächstes folgt ein Eintrag über die Stadt Heidelberg. Hier ziehen wir zum Vergleich sowohl den Text in der englischen als auch den in der deutschen Wikipedia heran. Alle drei Enzyklopädien widmen der Universitätsstadt nicht viele Worte. Bei Encarta sind es 2700 Zeichen, bei der englischen Wikipedia 1600, bei der deutschen 1300.
Der Encarta-Text erzählt kurz von Industriezweigen, Gebäuden (insbesondere dem Heidelberger Schloss) und Geschichte und erwähnt das Heidelberger Weinfass sowie den papstkritischen Autor Hieronymus von Prag. Er enthält einen Verweis auf den Encarta-Atlas, zwei Bilder und zwei Quellentexte über Heidelberg; einen Bericht von Victor Hugo und ein Gedicht von Friedrich Hölderlin. Insgesamt also ein runder, wenn auch etwas knapper Artikel.
Der englische Text ist noch kürzer und erwähnt kurz die geographische Lage der Stadt und beschreibt ihr Ambiente ("eine Mischung aus Tradition und Moderne" - etwas banal). Die Geschichte wird in Bullet-Points abgehandelt. Dafür gibt es mehr Querverweise auf bedeutende Akademiker, die sich in Heidelberg aufhielten: Georg Hegel, Hans-Georg Gadamer, Jürgen Habermas und Karl-Otto Apel. Der deutsche Text ist stichwortartig, verweist auf die verschiedenen Stadtteile und enthält lieblos zusammengeworfene Weblinks. Dafür findet sich darin ein Foto, das in der englischen Version (noch) nicht enthalten ist.
Der Scrollbalken führt uns nun zum deutschen Regisseur Rudolf Thome, über den Encarta in drei Absätzen zu berichten weiß. Seine Arbeiten werden - wieder kein NPOV bei Encarta - als "Meisterwerke des Neuen deutschen Films" bezeichnet. Weder die deutsche noch die englische Wikipedia erwähnen ihn.
Der nächste Text ist ein Absatz über Medienerziehung, die Encarta als "den Versuch, Kindern und Heranwachsenden Kompetenz .." - man kann sich den Rest denken - definiert. Zielführende Internetnutzung, Unterscheidung von Information und Werbung, Medien und Gewalt werden kurz erwähnt. Der Text ist banal und enthält keine Details, die man sich nicht bereits aus dem Titel denken kann. Ein Äquivalent unter dem gleichen Titel existiert weder in der englischen noch der deutschen Wikipedia, der erschreckend unterentwickelte Text Mass media erwähnt das Problem der Mediengewalt nicht. Der deutsche Text Fernsehen geht kurz auf Medienwirkung, Mediengewalt und Medienpädagogik ein und verweist auf einen noch nicht existenten Artikel gleichen Namens. Im englischen Television findet sich darauf kein Hinweis, und auch die Zensurdebatte in den USA wird dort nicht erwähnt - lediglich ein unscheinbarer Hinweis auf den V-Chip verrät mehr. Hier müssen beide Enzyklopädien noch Inhalte und Struktur schaffen.
Wie sieht es bei politischen Figuren aus, die im Westen weitgehend unbekannt sind? Encarta liefert per Zufall eine verhältnismäßig ausführliche Kurzbiographie des kambodschanischen Prinzen Samdech Norodom Ranariddh. Wikipedia ist der Mann weitgehend unbekannt, lediglich der aus dem CIA World Factbook importierte Artikel Politics of Cambodia verweist auf einen wiederum nichtexistenten Text. Tatsächlich gibt es auf Wikipedia offenbar keinen Kambodscha-Experten - die meisten relevanten Texte sind knapp und wenig editiert.
Jagd nach Diamanten
Unter dem Namen "Brilliant Prose" fasst die englische Wikipedia die angeblich qualitativ hochwertigsten Texte zusammen - einen Abstimmungsprozess gibt es nicht, das Wiki-Prinzip soll sicherstellen, dass schlechte Texte entfernt werden. Werfen wir also einen Blick auf die entsprechenden Artikel.
Da wäre zum Beispiel der Text über das Milgram-Experiment, das die Autoritätshörigkeit von Versuchssubjekten feststellen sollte, indem sie dazu aufgefordert wurden, anderen Versuchsteilnehmern Elektroschocks zu verpassen. Mit 5800 Zeichen ist er in der Tat ausführlich. Er beschreibt die Methodik und Ergebnisse von Milgrams Studien und auch die dadurch aufgeworfenen ethischen Fragen und zitiert jüngere Forschungen. Es folgen Querverweise und Quellenangaben sowie ein Link auf Milgrams Text "The Perils of Obedience", der im Volltext verfügbar ist. Weder das Experiment noch Stanley Milgram werden in Encarta mit einem Wort erwähnt - ein echtes Defizit der teuren Multimedia-Enzyklopädie.
Der Artikel über Stephen King ist mit 10100 Zeichen fast doppelt so lang wie sein Encarta-Pendant. Das liegt vor allem an der ausführlichen Bibliographie, der Text diskutiert eher Kings Methoden als seine Werke, während Encarta stärker auf die Inhalte eingeht. Kein Wunder: Bei Wikipedia finden sich über zahlreiche von Kings Büchern eigene Artikel, die vom einfachen "Stumpf" bis zur ausführlichen Inhaltsangabe reichen, entsprechende Zusammenfassungen wären im Haupttext redundant.
Der Beitrag über den von Computersystemen verwendeten ASCII-Standard zeigt die Detailverliebtheit der Wikipedianer. Er geht auf Geschichte und verschiedene Varianten des Standards an und enthält die relevanten Tabellen, die u.a. die Kontrollzeichen des ASCII-Standards auflisten und benennen. Die Zeichen sind in Binärform, Dezimal- und Hexadezimaldarstellung aufgelistet. Der Encarta-Text ist mit 2200 Zeichen weniger als halb so lang und enthält keine Tabellen.
|
Neben der Informatik ist auch die Philosophie eine von Wikipedias starken Seiten. Ockhams Rasiermesser ist ein bedeutender wissenschaftsphilosophischer Grundsatz, der besagt, dass komplexe Erklärungen einfachen nicht ohne Notwendigkeit vorzuziehen sind. Der Wikipedia-Artikel ist zwar nicht unbedingt brillant, geht aber im Detail auf die Geschichte und moderne Anwendung ein und liefert ein humorvolles Anwendungsbeispiel: Wenn ein Baum im Sturm umfällt, liege es näher, dies mit dem Sturm zu erklären als mit 200 Meter großen marodierenden Außerirdischen. Er erklärt die Anwendung des Prinzips in der Statistik und Religionskritik und enthält zahlreiche hilfreiche Querverweise.
Encarta hat keinen Artikel über Ockhams Rasiermesser, es wird lediglich im Text über Ockham selbst in zwei Sätzen erwähnt. Im zweiten Satz heißt es: "Allerdings geht [die] bekannte Formel [des Prinzips] 'entia non sunt multiplicanda sine necessitate' ... nicht auf Ockham zurück", was man leicht fehlinterpretieren kann: Ockhams Rasiermesser sei nicht seine Erfindung gewesen. Dabei drückte sich Ockham lediglich etwas anders aus ("Pluralitas non est ponenda sine neccesitate" - "Ohne Notwendigkeit soll keine Vielfältigkeit hinzugefügt werden").
Auch Sprachen sind eine von Wikipedias Spezialitäten. Der Artikel über Hebräisch ist auf fünf Seiten verteilt (Geschichte, Phonologie, Morphologie, Grammatik und Alphabet) und stellt mit insgesamt etwa 30000 Zeichen eine detaillierte Einführung dar. Trotz guter Struktur kann der Encarta-Text mit 6000 Zeichen hier nicht mithalten.
Mit rund 16500 Zeichen ist auch der Text über das Brettspiel Go deutlich länger als sein Encarta-Pendant (4500 Zeichen). Er geht im Detail auf die Regeln ein und vergleicht Go mit anderen Spielen, Spielzubehör wird ebenso diskutiert wie die von professionellen Go-Spielern verwendeten Ranking-Verfahren. Da wirkt die Abhandlung der Geschichte in vier Absätzen fast schon knapp. Doch der Go-Artikel ist damit noch nicht zu Ende. Er enthält Verweise auf Detail-Artikel über Regeln, Strategien, Sprichwörter und bekannte Spieler, die zusammen noch einmal rund 25000 Zeichen ausmachen - fast könnte man meinen, in einem Go-Wiki gelandet zu sein.
Der Encarta-Artikel über Go enthält eine Zusammenfassung der Regeln und eine kurze Geschichte, doch auch die Regelerklärung ist in Wikipedia in Form einer kompakten Liste im Haupttext und einem Verweis auf den Detailartikel deutlich besser gelöst. Der Encarta-Text enthält mysteriöserweise keinen einzigen Weblink, während es bei Wikipedia gleich elf allein im Hauptartikel sind (wobei natürlich auch die Möglichkeit des Online-Spiels erwähnt wird), auch eine Go-Newsgroup wird referenziert, dafür gibt es nur eine Literaturangabe. Das Poker-Universum in Wikipedia ist noch einmal eine Nummer größer - allein der Artikel über die Spielvariante des Draw Poker ist mit rund 20000 Zeichen fast dreimal so lang wie der gesamte Encarta-Text über Poker (7000 Zeichen).
Die deutsche Wikipedia hat eine ähnliche Liste der exzellenten Artikel, doch sie ist noch relativ leer. Dort aufgeführt ist zum Beispiel der Artikel Kondom, der zwar noch einige stilistische Unfeinheiten aufweist, aber mit etwa 6300 Zeichen bereits recht ausführlich ist. In Encarta gibt es keinen eigenen Artikel über Kondome, der lange Text über Empfängnisverhütung geht in rund 1200 Zeichen darauf ein. In Wikipedia finden sich hier auch Gebrauchshinweise und Links, die in der Encarta fehlen.
Der deutsche Wikipedia-Text über Patente ist deutlich ausführlicher und kritischer als der Encarta-Artikel über das Patentrecht, und auch der deutsche Artikel über die Maul- und Klauenseuche ist ausführlicher als das Encarta-Äquivalent, geht aber kaum auf die internationale Verbreitungsentwicklung ein.
Wie sieht es nun bei kontroversen Themen aus, bei denen man vermuten könnte, dass eine klassische Enzyklopädie sie aus politischen Gründen nicht behandelt? Traut sich die Encarta, über Menschenversuche der CIA zu berichten? Präsentiert sie sachliche und aktuelle Informationen über geheimnistuerische Organisationen wie die Bilderberger und die Trilaterale Kommission?
Der Encarta-Artikel über Verschwörungstheorien definiert sie als "Versuche, politische Geschehnisse auf ein rational nicht erklärbares, meist für böse gehaltenes Interessen- oder Machtgeflecht zurückzuführen", und hält sie für den "Ausdruck totalitärer Systeme". Es folgt ein wenig Sozialpsychologie: "Verschwörungstheorien tragen zu einer (trügerischen) Selbstvergewisserung bei, indem sie komplexe Zusammenhänge simplifizieren und durch die Zuweisung von Schuld uneingestandene Ängste in Wut und Hass auf eine identifizierbare Gruppe umlenken." Zu guter Letzt ein Hinweis auf antisemitische Verschwörungstheorien, das Ganze erstreckt sich über drei Absätze.
Ein solcher Artikel, der mehr oder weniger der Meinung eines Autors entspricht, wäre in Wikipedia kaum möglich. Die Analyse ist subjektiv und verletzt damit die heilige NPOV-Regel. Die Beispiele scheinen bewusst wegen ihrer negativen Konnotationen gewählt zu sein. Der Artikel erinnert so an ähnliche Veröffentlichungen in Mainstream-Medien wie der New York Times oder dem SPIEGEL, die meist einem Standard-Schema folgen: "Im Internet kann jeder alles publizieren. Deshalb gibt es dort viele verrückte Ideen, wie z.B. die Reptilianer und die jüdische Weltverschwörung. Verschwörungstheorien vermitteln ihren Anhängern ein Gefühl von Sicherheit und Geborgenheit und sind meist unwiderlegbar." Es folgt in solchen Artikeln dann meist ein Beispiel einer plausibel klingenden Verschwörungstheorie, die widerlegt wurde ("Bilder von jubelnden Palästinensern nach dem 11. September waren falsch") - und die Welt ist in Ordnung.
Der Wiki-Artikel Conspiracy theory hat derzeit einen Umfang von etwa 23500 Zeichen (Encarta: 2000 Zeichen). Die Einleitung ist umfangreicher als der gesamte Encarta-Text. Sie ist neutraler geschrieben und enthält bereits zwei interessante Verweise: Auf die Men in Black aus der UFO-Szene und auf die Anti-Psychiatrie-Bewegung, die vermutet, dass unliebsame Zeitgenossen schlicht für geistesgestört erklärt und weggesperrt werden. Wer möchte, kann sich in den beiden umfassenden Artikeln über diese Phänomene weiter informieren.
Der Artikel verweist im nächsten Teil kurz darauf, dass Verschwörungen erwiesenermaßen existieren und differenziert die Verschwörungstheorie vom Begriff der Verschwörung selbst:
"Yet if conspiracy is taken to include every back-room alliance, every unpublishable 'understanding' between political or business persons, every cartel, and so forth - every secret plan between two or more parties at the expense of a third - then conspiracy is so widespread as to be unremarkable. It is in this sense that conspiracy theory collector Colin Wilson has remarked that conspiracy is 'the normal continuation of normal politics by normal means.'"
Er stellt weiter fest, dass die Bezeichnung "Conspiracy Theory" sich hervorragend eignet, um soziale und politische Kritik zu verspotten und macht einen Unterschied zwischen Verschwörungstheorien und Anschuldigungen von Verschwörungen. Es folgt eine Zusammenfassung verschiedener Elemente von Verschwörungstheorien:
Der Artikel enthält auch eine kurze Abhandlung über Verschwörungs-Folklore und Verschwörungs-Fiktionen wie die "Illuminatus!"-Trilogie, Umberto Ecos "Foucaultsches Pendel" und Pynchons "Versteigerung von No. 49". Dann ein typischer Wikipedia-Schnitzer, der sicher bald verschwindet: "Etwas über Oliver Stone und JFK (Film) hier - habe ich nicht gesehen".
Nun folgt der Abschnitt "Real life imitates conspiracy theory", der drei reale Beispiele für problematische Regierungsaktivitäten auflistet, deren Existenz unumstritten ist: das "Information Awareness Office", das detaillierte Informationen über US-Bürger sammeln soll; das Gedankenkontroll-Programm MKULTRA und das Abhörnetz Echelon. Über jedes dieser Themen gibt es einen eigenen Wikipedia-Artikel.
Nach diesem Text stößt der Leser auf eine horizontale Linie und den Hinweis "needs encyclopediafying", der sich auf den darunter befindlichen Textteil bezieht. Eine solche Mischung aus Text mit noch nicht vollständig überarbeiteten Bestandteilen tritt vor allem auf, wenn Artikel mit anderen verknüpft werden, derjenige, der die Operation vorgenommen hat, aber zu faul war, für Konsistenz zu sorgen. Unter dem Artikel über Verschwörungstheorien findet sich eine lange Liste von spezifischen Theorien in verschiedenen Kategorien, über die es meist jeweils eigene Artikel gibt. Die Form ist damit insgesamt noch eher unbefriedigend, der Inhalt ist aber der Encarta um Größenordnungen überlegen.
Gilt das auch für die einzelnen behandelten Themen? Für einen großen Teil schon. Der Text über das CIA-Programm MKULTRA ist mit rund 15000 Zeichen z.B. sehr umfangreich, er beruht ursprünglich auf einer Public-Domain-Veröffentlichung, wurde aber massiv überarbeitet. Er geht detailliert auf die unter der Abkürzung laufenden Programme zur Gehirnkontrolle ein, bei denen mit Drogen und Elektroschocks Versuchspersonen gefügig gemacht werden sollten, und beschreibt auch die Geschichte des Projekts, erste Enthüllungen durch die New York Times und die Gerichtsprozesse, die folgten.
Encarta erwähnt MKULTRA mit keinem Wort.
Nicht ganz so krass ist es beim Counter Intelligence Program (COINTELPRO) des FBI, das sich gegen linke politische Gruppierungen richtete. Encarta erklärt das Programm in einem langen Absatz im Artikel über das FBI: ".. richteten sich u.a. gegen Interessengruppen der Schwarzen, Bürgerrechtsorganisationen, sozialistische Organisationen, aber auch gegen rassistische Gruppierungen und die so genannte Neue Linke, die gegen den Vietnamkrieg war. Im Verlauf dieser und anderer Programme verübte das FBI illegale Einbrüche in Wohnungen oder Firmen, hörte ungenehmigt Telefongespräche ab, sammelte delikate Informationen, um diese für politische Zwecke zu nutzen. Das FBI ließ diese Informationen auch an die Medien durchsickern .."
Die Überwachung Martin Luther Kings, der mit Informationen über eine außereheliche Affäre diskreditiert werden sollte, wird genannt. Der entsprechende Wikipedia-Artikel ist trotzdem ausführlicher und beschreibt die Methoden des Programms und seine Geschichte im Detail, natürlich mit Links auf kritische Websites.
Weder die Trilaterale Kommission noch die Bilderberger werden in Encarta erwähnt. Sie zählen zu den Lieblingsobjekten der Verschwörungstheoretiker, da sie nachweislich existieren, trotzdem aber ihre High-Society-Treffen weitgehend geheimhalten. Wikipedia hat über beide Gruppen immerhin kleine Stubs ( Bilderberger Group und Trilateral Commission), die sicher im Laufe der Zeit zu ansehnlichen Artikeln anwachsen werden. Der Text über Echelon ist eher apologetisch, aber weitaus umfassender als die kurze, faktenarme Zusammenfassung im Encarta-Artikel über die NSA. Wikipedia enthält erwartungsgemäß Hinweise auf aktuelle Entwicklungen in Bezug auf Terrorismus, die bei Encarta fehlen.
Die Abhandlung der Drogenproblematik ist in Wikipedia erheblich ausführlicher. Neben dem erwähnten Text über den "War on Drugs" gibt es auch eine rund 19500 Zeichen lange Analyse des Einsatzes von Marihuana als Schmerzmittel, was in den USA ein extrem brisantes Thema ist. Darin findet sich eine Darstellung der momentanen Situation in den verschiedenen Bundesstaaten, die oft in Reibereien mit der Regierung geraten, weil die einen massiven Anti-Legalisierungs-Kurs vertritt. Man erwartet zwar in der deutschen Encarta nicht unbedingt solche Details, doch zumindest eine Kurzzusammenfassung wäre wünschenswert.
Ein ähnlich schwaches Bild gibt die Encarta beim Thema des Anti-Amerikanismus ab, das in der von Amerikanern dominierten englischen Wikipedia verhältnismäßig neutral behandelt wird und die Argumente der Amerika-Kritiker nicht verschweigt. Encarta erwähnt den Anti-Amerikanismus zumindest namentlich nur im Artikel über Osama bin Laden.
Wiki-News und Wiki-Sex
Auch in anderen Bereichen ist Wikipedia klassischen Werken um einiges voraus. Encarta kann bestenfalls über das Internet nachträglich aktualisiert werden, gedruckte Werke haben noch größere Aktualitätsprobleme. Wikipedia ist dagegen oft minutenaktuell, Wikipedianer werden oft durch Meldungen auf News-Websites und Weblogs zu Artikeln inspiriert. Es gibt in Form der Current Events sogar eine Art Wiki-Tageszeitung, die täglich relevante News zusammenfasst und auf Hintergrundartikel verweist. Die Selektion ist teilweise recht willkürlich, was an der noch relativ geringen Zahl der hier beteiligten Redakteure liegt.
|
Nach Monatsende werden die jeweiligen News archiviert und bleiben so im Gegensatz zu den meisten Online-News-Angeboten für historische Zwecke erhalten. Die meist als Quellen genannten URLs werden jedoch nach gewisser Zeit ablaufen, was langfristig zu Belegzwecken eine zusätzliche Quellenrecherche erforderlich macht.
Auch an Artikeln über Sex-Praktiken fehlt es bei Wikipedia nicht. Sex-Stellungen und sexuelle Fetische werden im Detail behandelt. Über Themen wie Sado-Masochismus findet man um Größenordnungen mehr Material als in jeder klassischen Enzyklopädie. Bizarre Neigungen wie Zoophilie werden ebenso diskutiert wie größere gesellschaftliche Probleme - Schwangerschaften, sexueller Missbrauch und die beides umgebende Hysterie. Selbst über "Nackte Promis im Internet" gibt es einen eigenen sachlichen Artikel, der vor allem durch entsprechende Suchmaschinen-Anfragen inspiriert wurde und täglich einige Sucher zu Wikipedia leitet, die wahrscheinlich nicht zu dauerhaften Wikipedia-Autoren werden.
Was fehlt
In der englischen Wikipedia sind die meisten Themenbereiche zumindest mit Basisinformationen gefüllt. In der deutschen klaffen dagegen noch riesige Lücken, wie man schnell feststellt, wenn man Kategorien wie z.B. Bildende Kunst durchblättert. Eine Spezialfunktion der Software zeigt an, welche Artikel von vielen anderen verlinkt werden, aber noch nicht existieren. Auf der deutschen Wikipedia sind dies derzeit so elementare Dinge wie Magen, Kreislauf, Emanzipation, Mystik, Realismus, Supermarkt, Befruchtung, Kalk, Sinai, Hermes, Zeremonie, Rationalismus.. Von einer vollständigen Enzyklopädie kann hier also noch nicht annähernd die Rede sein - bisher sind es ja auch nur rund 15000 Artikel.
Ganz anders auf der englischen Wikipedia - die "most wanted" sind hier meist Detailartikel wie "Grammy Awards des Jahres 1988", die von vielen Seiten referenziert werden (in diesem Fall als Teil einer Navigationshierarchie). Andere fehlende Artikel wie "James A. Michener" oder "University of Leipzig" sind zwar leicht irritierend, aber ähnlich verzeihlich wie manche Encarta-Lücken.
Der Artikelstatistik nach befindet sich die deutsche Wikipedia im Mai 2003 dort, wo die englische schon im Oktober 2001 war. Realistische Prognosen sind angesichts der technischen Situation von Wikipedia schwer möglich - die Software und der Server werden mit dem Benutzeransturm kaum noch fertig, und es ist unklar, wie lange diese Probleme noch andauern.
Wikipedia funktioniert - Schlussfolgerungen
Der Zufallstest zeigt, dass Wikipedia selbst im Durchschnitt in einigen Bereichen bereits deutlich besser abschneidet als das kommerzielle Gegenstück Encarta, das durchaus repräsentativ für eine Vielzahl von Enzyklopädien stehen kann. Beide haben Lücken - Encarta behandelt bestimmte Themen wie Sex und Software nur sehr beschränkt, während Wikipedia nach dem Open-Source-Prinzip funktioniert: Wo sich niemand verantwortlich fühlt, fehlen wichtige Texte noch. Manche Nation oder politische Figur wird deshalb sträflich vernachlässigt, was sich aber sicher mit weiterem Wachstum ändern wird. Und wenn es um kontroverse Themen geht, hat Wikipedia fast immer die Nase vorn: Der neutrale Standpunkt (NPOV) wird in der Regel gewahrt, und bestimmte Themen aus sensitiven Bereichen werden von anderen Werken größtenteils oder vollständig ignoriert.
Wikipedia funktioniert. Wie gut sie funktioniert, lässt sich schwer quantifizieren, da z.B. der durchschnittliche Fehleranteil pro Artikel unbekannt ist. Es hängt auch davon ab, ob man Formfehler für schwerwiegend hält, denn davon gibt es zahlreiche. Inhaltlich kann sich Wikipedia mit millionenschweren Projekten wie Encarta messen, was nach gerade etwas mehr als 2 Jahren eine schwer zu fassende Leistung ist.
Mit unglaublicher Geschwindigkeit arbeitet, rotiert, tanzt das Wikipedia-Netz der Gehirne, ein Phänomen, das bisher nicht annähernd genug wissenschaftliche und journalistische Aufmerksamkeit erfahren hat. Nicht Professoren und nicht Firmen haben die Wikipedia-Infrastruktur gebaut - es war eine kleine Handvoll motivierter Freiwilliger. Wie GNU und Linux, wie das World Wide Web, wie Weblogs entstanden Wikis und schließlich Wikipedia nicht, weil sie von oben geplant wurden. Sie wurden von unten gebaut, und wenn Universitäten involviert waren, dann meist in der Form, dass sie ihren Studenten genügend Zeit für sinnvolle Tätigkeiten neben dem Studium ließen.
Wikipedia ist sexy, deshalb berichtet jedes Magazin gerne mal darüber auf seiner Internet-Seite. Doch was dieses Projekt bereits geleistet hat, entzieht sich dem Vorstellungsvermögen der meisten Begutachter. Neben dem täglich wachsenden Nutzen der freien Enzyklopädie verrät sie uns viel über das Menschsein an sich. Von den vielen tausend Änderungen die jeden Tag an Wikis gemacht werden, ist nur ein verschwindend kleiner Prozentsatz "bösartig", und selbst von diesen kann man viele als einmalige Experimente abtun. Wo ist die Profitgier, die Geltungssucht, die Starrköpfigkeit, die wir uns gegenseitig so gern zuschreiben? Sicher: All diese Eigenschaften findet man auch bei Wikipedianern - doch es waren technische, nicht soziale Probleme, die das Projekt bisher in seinem Wachstum beschränkt haben.
Während das Internet von vielen noch gemieden wird, weil sie es nicht verstehen oder fürchten, entstehen dort Dinge, die vor 10 Jahren als ferne Science Fiction abgetan worden wären. Das Netz hält uns den Spiegel vor und zeigt uns unsere Zukunft und unser Potenzial. Jetzt, hier und heute werden die Regeln definiert, die Fundamente gelegt für Entwicklungen, die unsere Kultur für immer verändern werden. Wer dies nicht begreift, läuft Gefahr, die falschen Weichen zu stellen.
Welche Möglichkeiten hätte Wikipedia, wenn das Urheberrecht nicht jedes moderne Werk de facto für die Ewigkeit schützen würde? Welche Gefahr droht dem Projekt dagegen, wenn Zensoren und Bürokraten den internationalen Datenverkehr kontrollieren? Es liegt in der Verantwortung jedes einzelnen, diese Chancen und Risiken zu erkennen - und das Richtige zu tun.
Diderots Traumtagebuch
Tanz der Gehirne, Teil 3
Wikipedia ist nicht die einzige Website, deren Inhalte von vielen Nutzern gemeinsam erstellt werden. Spin-Off-Projekte verwenden die Wikipedia-Software für andere Ziele, Info-Communities wie Everything2 und H2G2 heben sich durch eigene Regeln, Funktionen und Oberflächen von der Welt der Wikis ab. Doch während in Wikis jeder alles bearbeiten darf, wird hier getrennt gewerkelt, häufig an Artikeln zum gleichen Thema. Auch diese Communities zeigen, wie groß die Bereitschaft der Nutzer ist, ihr gesammeltes Wissen anderen frei zur Verfügung zu stellen - aber auch, wie bedeutsam die Idee des "Open Content" ist, und wie schwer es sein kann, hochwertige Informationen zu finden.
Die frei verfügbare Wikipedia-Software ist ideal für Wissensbasen aller Art, und so verwundert es nicht, dass verschiedene Spin-Off-Projekte entstanden sind. Das bekannteste davon ist wohl die Disinfopedia von Sheldon Rampton. Rampton ist zusammen mit John Stauber Autor der Bestseller "Toxic Sludge is Good For You" und "Trust Us, We're Experts", die im Detail erklären, wie PR-Agenturen und Think-Tanks die öffentliche Meinung zugunsten ihrer Auftraggeber beeinflussen. Die Bücher handeln von der Pseudowissenschaft der Tabakindustrie und vom Aufbau falscher "Graswurzel-Bewegungen", die sich im Namen der Konsumenten gegen deren Rechte engagieren; von Auftragswissenschaftlern und solchen, deren Forschungsergebnisse gezielt vertuscht wurden; vom Einsatz von Propaganda in Kriegen und Unternehmenskrisen.
Rampton hat sich damit international einen Namen als "Desinfo"-Experte gemacht; im Rahmen seiner Organisation Center for Media and Democracy betreibt er bereits seit längerem die Website P.R. Watch, die einen täglichen Newsletter über die Machenschaften der Propaganda-Industrie herausgibt. Von Wikipedia erfuhr er erstmals auf der World Information Conference in Amsterdam im Dezember 2002. Sofort war er von der Idee begeistert und nutzte seine IT-Kenntnisse, um mit der Software zu experimentieren. Die erste Version von Disinfopedia machte er noch im gleichen Monat ausgewählten Besuchern zugänglich, die nächsten Wochen verbrachte er damit, die Website mit Inhalten zu füllen. Am 10. März ging das Projekt schließlich an die Öffentlichkeit.
Die Website grüßt mit dem ehemaligen Logo der Pentagon-Überwachungsinitiative Total Information Awareness: das leuchtende Auge in der Pyramide, das die ganze Welt erfasst - ein gefundenes Fressen für Verschwörungstheoretiker. "Total Disinformation Awareness" verspricht die Website, und verzeichnet mittlerweile immerhin um die 1000 Texte. Dabei handelt es sich oft um längere Artikel aus den Büchern oder Zitate von relevanten Websites.
Wie Wikipedia steht auch Disinfopedia unter der GNU FDL. Dank der kompatiblen Lizenzen können Texte direkt aus Wikipedia übernommen werden. Anstatt der Doktrin vom neutralen Standpunkt soll sich in Disinfopedia aber alles "fair und akkurat" abspielen; wenn ein Standpunkt nur von einer Minderheit aus finanziellen Motiven verbreitet wird, verdient er in Disinfopedia keine ausführliche Behandlung.
Die Meinungsmacher
Wie Propaganda funktioniert soll mit Fallstudien illustriert werden. Der Artikel Coalition for Southern Africa erklärt beispielsweise, wie Shell mit Hilfe einer PR-Agentur versuchte, Boykotte wegen seiner Geschäftsbeziehungen zum Apartheid-Regime in Südafrika abzuwenden: Eine "Koalition für Südafrika" wurde gegründet, die in der Öffentlichkeit betonen sollte, wie sehr sich Shell doch gegen Apartheid und für die Gleichstellung von Schwarzen einsetze. Auch aktuelle Themen werden behandelt: Der öffentlich organisierte Sturz der Hussein-Statue in Bagdad wird kurz dokumentiert, der Artikel über SARS vergleicht die Reaktion auf die Lungenkrankheit durch die kanadische und die chinesische Regierung.
Ein Verzeichnis listet die zahlreichen industriefinanzierten "Experten" auf, die als Kronzeugen gegen "Mythen" wie die globale Erwärmung oder die Schädlichkeit des Passivrauchens angeführt werden, aber auch Think Tanks und industrie-freundliche Organisationen werden katalogisiert.
Disinfopedia ist eine wichtige Ressource, doch das Themenspektrum erfordert viel Vorwissen. Bisher gibt es das Projekt nur auf Englisch, eine deutsche Version ließe sich bei Bedarf aber leicht aufsetzen. Bleibt die Frage, inwieweit Disinfopedia selbst zum Ziel von Desinfo-Kampagnen werden könnte. Nicht industriefreundliche Kampagnen wären das Problem, sondern hochmotivierte Nutzer, die scheinbar korrekte Informationen mit unscheinbaren Fehlern, falschen Quellenangaben usw. einfügen oder die Glaubwürdigkeit des Projekts auf andere Weise unterminieren.
Andere Spin-Off-Projekte von Wikipedia existieren. Die AsiaOSC Open Source Knowledge Base und das deutsche OpenFacts-Projekt verfolgen ähnliche Ziele. Beide wollen das Wissen der OSS-Bewegung dokumentieren, wobei sich AsiaOSC auf Entwicklungen im asiatischen Raum konzentriert und OpenFacts auf die Erstellung von Dokumentation. OpenFacts ist verhältnismäßig inaktiv, aber eng an die BerliOS-Entwicklerplattform gekoppelt - jedes bei BerliOS registrierte Projekt erhält automatisch eine Seite im Wiki.
Das Consumerium-Projekt möchte freie Software für die Verwaltung von Produktinformationen für Konsumenten entwickeln und bedient sich zur Informationsorganisation eines Wikipedia-basierten Wikis. Unilang dagegen ist eine schnell wachsende Community "von und für Sprach-Freaks", die Informationen über Grammatiken und Vokabular der verschiedensten Sprachen sammelt. Das Wikipedia-Team hat zu einem ähnlichen Zweck das Wiktionary-Projekt gestartet, das sich zum weltgrößten Wörterbuch in allen Sprachen entwickeln soll. Mit immerhin schon rund 2700 Einträgen wächst Wiktionary recht schnell, doch hier gibt es zahlreiche kostenlose Alternativen im Web, die i.d.R. noch deutlich umfangreichere Infos bringen. Alle diese Projekte sind Open Content, OpenFacts verwendet anstelle der FDL die Public Domain.
Wikipedia-Spinoffs profitieren von der schnellen Entwicklung der Software, unterscheiden sich aber natürlich in ihrer Funktionalität nicht wesentlich vom großen Vorbild. Anders sieht es bei den Projekten Everything2 und H2G2 aus: Bei beiden handelt es sich um offene Wissensdatenbanken, doch sie funktionieren gänzlich anders als die bisher diskutierten Wikis.
Slashdots kleiner Bruder
Everything2 war ursprünglich als Erweiterung des Geek-Weblogs Slashdot gedacht. Im Frühjahr 1998 strickte Nate Oostendorp, Hacker und Freund des Slashdot-Gründers Rob Malda, die erste Version von "Everything" zusammen, die unter everything.slashdot.org zu finden war. Wie der Name andeutet, sollte die Website jedem Besucher erlauben, zu praktisch jedem Thema Hintergrundartikel zu schreiben - zunächst waren das aufgrund der Nutzer-Community natürlich die typischen Slashdot-Themen wie Linux, PC-Hardware, Star Wars und Anime.
|
1999 wurde die Software neu geschrieben, und am 13. November ging die Website unter dem Namen Everything2.com erneut an den Start, jetzt deutlich abgekoppelt von Slashdot. Die Everything-Hacker gründeten eine Firma namens Blockstackers, welche die Software für andere Anwendungszwecke vermarkten sollte. Daneben schaltet Everything2 Werbebanner und ruft regelmäßig zu Spenden auf.
Während Wikipedia-Inhalte dank der GNU Free Documentation License frei kopierbar sind und es auch bleiben, gilt für die Everything2-Texte das klassische Urheberrecht: Die Firma Blockstackers erhält lediglich das nicht-exklusive Recht zur Verbreitung über die Website, alle weiteren Rechte verbleiben bei den Nutzern. Wer also einen Artikel in anderer Form weierverwerten möchte, muss jeweils den individuellen Nutzer kontaktieren und um Erlaubnis bitten. Die Everything2-Software ist dagegen Open Source.
Everything2 enthält weder Bilder noch WWW-Links (inoffiziell werden sie manchmal angegeben, werden aber von der Software noch nicht einmal automatisch "klickbar" gemacht und bleiben folglich reiner Text). Es handelt sich also um ein weitgehend geschlossenes, textbasiertes System. Die einzige offizielle Sprache ist Englisch. Kein Open Content, keine Bilder, keine URLs, keine deutsche Version - warum sich also überhaupt damit befassen?
Insgesamt befinden sich im System derzeit fast 500.000 Artikel ("Write-Ups"), knapp 65.000 Benutzer haben sich registriert. Damit ist Everything2 rein nominal größer als Wikipedia. Wie groß die Site wirklich ist, lässt sich nicht prüfen, da die Daten nicht frei heruntergeladen werden können. Veröffentlichte statistische Analysen beschränken sich auf Systemdetails.
Was ist die Matrix?
Everything2 unterscheidet zwischen Write-Ups und "Nodes". Ein "Node" ist ein gemeinsamer Oberbegriff, unter dem sich verschiedene Artikel befinden können, auch zu völlig unterschiedlichen Themen. Nodes werden wie bei Wikis erstellt, indem man einem Link zu einem nichtexistenten Artikel folgt und diesen anlegt. Doch hier gibt es einen wesentlichen Unterschied zu Wikipedia: Verweise auf nichtexistente Artikel werden genauso dargestellt wie solche auf vorhandene Texte. In einem Text mit Hunderten von Links gibt es außer "Versuch und Irrtum" also keine Möglichkeit festzustellen, welche Artikel bereits geschrieben wurden. Immerhin wird bei einem Klick auf einen nichtexistenten Link eine Volltextsuche durchgeführt, die häufig relevante ähnliche Treffer zu Tage fördert.
Schreiben kann man bei Everything2 erst, nachdem man sich registriert hat, was die hohe Zahl angemeldeter Nutzer erklärt. Ein Write-Up gehört dem jeweiligen Autor, das Editieren des gleichen Textes durch Dritte ist nicht möglich. Man kann allenfalls versuchen, dem jeweiligen Nutzer eine Nachricht zukommen zu lassen (dazu gibt es die "Chatterbox", eine Art Mini-Chat) und ihn bitten, fehlende Informationen zu ergänzen. So kommt es, dass häufig zu dem gleichen Thema eine große Zahl verschiedener Artikel mit unterschiedlichen Perspektiven existiert. Bei Wikis ist das anders: Dort wird praktisch jeder größere Artikel gemeinsam verfasst, Versuche, einen Artikel für sich zu beanspruchen, sind verpönt - eine Ideologie des Gemeinwissens, die man sonst nur in der Open-Source-Welt findet.
Um E2-Artikel zu schreiben, bedient man sich einer Untermenge der WWW-Sprache HTML; Absätze müssen mühselig mit "<P>"s voneinander getrennt werden. Links werden statt wie bei Wikipedia mit doppelten mit [einfachen eckigen Klammern] gesetzt. Everything2 ist von allen kollaborativen Systemen das Link-intensivste. Links werden von vielen Autoren als Mittel der Hervorhebung von Schlüsselphrasen in einem Text eingesetzt. Dabei macht es oft keinen Unterschied, ob jemals ein sinnvoller Text über die entsprechende Phrase geschrieben werden kann; im Gegenteil, wer seine Artikel nicht mit genügend Links übersät, wird schnell von anderen Everything2-Usern zurechtgewiesen. Alles in E2 ist darauf ausgelegt, den User im System zu halten. Der Weg des geringsten Widerstands soll es stets sein, zu anderen Texten weiter zu klicken oder eigene Artikel zu schreiben.
|
Eine E2-Innovation sind die sogenannten "Soft-Links". Da die Entwickler offenbar der Meinung waren, dass die zahlreichen von Autoren eingefügten Links immer noch nicht ausreichen, wird unterhalb der Liste der Write-Ups eine dynamische generierte Liste von bis zu 48 Links angezeigt. Dabei handelt es sich um eine nach Zahl der Klicks geordnete Liste von Artikeln, die Benutzer vom aktuellen Artikel aus besucht haben, oder von denen sie auf den aktuellen Artikel gekommen sind. Ein Soft-Link wird angelegt, sobald man einen "harten" Link in einem Text anklickt, oder wenn man auf einer Artikelseite die Suchfunktion nutzt und damit zu einem anderen Text navigiert. Aufgrund der Sortierung nach Popularität handelt es sich hier durchaus häufig um relevante Verweise. Das System erinnert so an ein neuronales Netz, in dem ständig dynamisch Verknüpfungen zu neuen Informationen entstehen und durch Verwendung intensiviert werden: eine interessante Idee.
Motivationskontrolle
Eine weitere E2-Eigenheit ist das "Abstimmungs- und Erfahrungssystem". Man darf nicht vergessen, dass E2 aus der Slashdot-Ecke kommt, folglich ist es wenig überraschend, dass die Entwickler von Rollenspielen wie "Dungeons & Dragons" beeinflusst wurden. Bei diesen Spielen, für die man keinen Computer braucht, schlägt sich der Spieler in einer Fantasiewelt mit Monstern oder anderen Gegnern herum. Zur Belohnung erhält er gelegentlich Waffen und Schätze, aber vor allem Erfahrungspunkte. Hat er genügend Punkte gesammelt, kann er zur nächsten "Stufe" aufsteigen, was seine Spielereigenschaften wie Stärke, Geschicklichkeit, Zaubersprüche usw. verbessert.
Diese Stufensysteme tragen wesentlich zum Suchtfaktor von Rollenspielen bei; wer zwei Jahre gespielt hat, um seinen Magier auf Stufe 17 zu befördern, wird diesen Fantasie-Charakter ungern aufgeben. Der Siegeszug der Online-Rollenspiele hat zu so bizarren Phänomenen wie dem Verkauf virtueller Waffen und Rüstungen oder gar ganzer Charaktere über eBay geführt. Mitunter werden solche Games als "Heroinware" bezeichnet, Software, die süchtig macht. Die Rollenspiel-Parodie ProgressQuest spielt sich dagegen von ganz alleine: Der "Spieler" muss nur den Rechner laufen lassen und kann zuschauen, wie sein Charakter die nächste Stufe erklimmt; den Highscore erreicht, wer am längsten warten kann. Und sogar hier scheint der bizarre Effekt des Erfolgserlebnisses zu funktionieren: Über 50.000 Benutzer haben sich das Programm heruntergeladen, die Bestenlisten sind dominiert von "Spielern", welche die 79. oder 80. Stufe erklommen haben.
Ein solches Motivationssystem lässt sich natürlich auch zweckentfremden, und es scheint nur eine Frage der Zeit zu sein, bis Manager ihre Angestellten wie Rollenspiel-Charaktere behandeln. Bei Everything2 ist das Erfahrungssystem vermutlich einer der Hauptgründe für die große Menge von Texten im System. Das System ist komplex: Insgesamt gibt es derzeit 13 Stufen, vom Initianten (Stufe 1) über den Schriftgelehrten (Stufe 4), Mönch (Stufe 5), Seher (Stufe 8) und Archivar (Stufe 9) bis schließlich zum Pseudo-Gott (Stufe 12) und - etwas enttäuschend - zum Pedanten (Stufe 13).
Um zur nächsten Stufe aufzusteigen, benötigt man jeweils eine bestimmte Zahl von Write-Ups und eine bestimmte Zahl von Erfahrungspunkten. Für Stufe 2 benötigt man 25 Write-Ups, bei Stufe 5 sind es schon 250 und bei Stufe 10 1215. Das System belohnt also Quantität, wie sieht es mit Qualität aus? Erfahrungspunkte (XP) sammelt man ebenfalls durch das Schreiben von Artikeln. Außerdem gibt es ein Bewertungssystem, das Nutzer ab Stufe 2 verwenden können: Man kann einen Text dann mit Plus oder Minus beurteilen, hat aber pro Tag nur eine begrenzte Zahl von Stimmen zur Verfügung, die mit der Stufe ansteigt. Eine hohe Bewertung gibt einen XP-Bonus, während eine negative Bewertung zu einem Malus führt. Wer also ständig negativ bewertete Artikel schreibt, wird nicht zur nächsten Stufe aufsteigen können.
XP werden für eine Vielzahl von anderen Anlässen vergeben, wozu auch die Bewertung von Artikeln selbst gehört - damit soll ein Anreiz geschaffen werden, Artikel im System zu lesen und zu beurteilen und jeden Tag die maximale Zahl von Stimmen zu verbrauchen.
Ein Redakteur hat's schwer
XPs zu sammeln ist deutlich leichter als das Schreiben von Artikeln. Das liegt auch daran, dass nicht jeder Artikel im System verbleibt. Artikel mit einer sehr negativen Reputation werden von den Everything2-Redakteuren und "Göttern" überprüft und gegebenenfalls gelöscht. Diesen zwei Benutzergruppen gehören insgesamt über 50 User an. Sie gehen auch selbst auf die Suche nach Artikeln, die sie für unbrauchbar halten, und können diese willkürlich löschen. Zu löschende Artikel werden kurzzeitig auf der Node Row platziert (der Name lehnt sich an "Death Row" an) und nach spätestens 24 Stunden vom System gelöscht.
Die Kriterien, denen ein Artikel genügen muss, um nicht gelöscht zu werden, sind nicht klar definiert, es gibt lediglich Tipps. Neulinge werden von Anfang an gewarnt, damit rechnen zu müssen, dass ein Großteil ihrer Artikel im "Node Heaven" landen wird, solange sie sich noch nicht im System auskennen. Tatsächlich hat es viel mit den Machtstrukturen zu tun, was akzeptabel ist und was nicht: Ein Stufe-10-Benutzer kann sich zweifellos mehr erlauben als ein Neuling und hat eine hinreichende Machtbasis, um die Löschung seiner Artikel zu verhindern.
|
Außer der erwähnten Chat-Funktionalität sind Diskussionen unerwünscht: Innerhalb von Write-Ups soll nur begrenzt auf andere Write-Ups Bezug genommen werden; sogenannte "Getting to know you"-Nodes, in denen ein Nutzer andere nach ihrer Meinung oder ihren Erfahrungen fragt, werden unverzüglich gelöscht. Ganz anders als bei Wikipedia wird über die Texte selbst kaum geredet.
Wer jetzt glaubt, Everything2 sei aufgrund der rigiden Löschungen eine Sammlung hochqualitativer Informationen zu jedem Thema, könnte falscher nicht liegen. Im Gegensatz zu Wikipedia ist E2 ein Dschungel, eine Mega-Datenbank mit einem enorm hohen Rauschpegel. Ein Zufallstest fördert die folgenden Seiten zu Tage:
Traumland
Wie wir gesehen haben, sind viele E2-Artikel Fiktion, Meinung oder purer Nonsens. Für jeden Tag gibt es außerdem ein sogenanntes "Day Log" (Beispiel: 21. Mai 2003), in dem Nutzer ihr Online-Tagebuch führen können. Daneben gibt es auch ein "Dream Log", wo Nutzer ihre Träume aufzeichnen können ( Beispiel).
Es wäre falsch, aus diesem Wust an persönlichen Aufzeichnungen zu schließen, es befänden sich keine enzyklopädischen Informationen auf E2. Das System macht es jedoch nicht besonders leicht, diese Texte zu finden. Eine Kategorisierung findet nur nach "Person", "Place", "Idea" und "Thing" statt, Oberverzeichnisse gibt es kaum. Und all die Bewertungen nützen nicht viel, da sie für den Normalbenutzer unsichtbar sind. Selbst wenn man sich registriert hat, kann man die Bewertung eines Artikels erst einsehen, wenn man selbst eine abgegeben hat. Die einzigen offen sichtbaren Bewertungen sind die sogenannten "Chings" oder "Cools", das sind besondere Auszeichnungen, die Nutzer höherer Stufen, Redakteure und Götter vergeben können. Doch diese sind so häufig, dass sie wenig hilfreich sind; auch einige der oben zitierten Texte sind "gecoolt" worden.
Bleibt noch die direkte Suche. Was taugt E2, wenn man nach konkreten Fakteninformationen sucht? Beispiel Homöopathie ( Homeopathy): Der entsprechende E2-Node besteht aus sechs Write-Ups, die der Leser für sich zu einem kohärenten Gesamtbild zusammenfügen muss. Der erste Text ist eine Mini-Zusammenfassung, der zweite erwähnt pro-homöopathische Forschungen zum "Gedächtnis des Wassers", der dritte bezeichnet die Idee als Quatsch und verweist auf die extreme Verdünnung der "Wirksubstanz", der vierte ist ein längerer pro-homöopathischer Text, der seine Haltung damit begründet, ein Placebo könne ja keinen Schaden anrichten und einige Homöopathie-freundliche Websites auflistet (in kleiner Schrift, damit sich niemand über die externen Links beschwert), der fünfte erklärt schließlich mathematisch, warum Homöopathie nicht funktionieren kann, und der sechste ist wieder einmal eine 1913-Webster-Definition (Homöopathie stammt ja aus dem 19. Jahrhundert).
Ähnlich sieht es bei fast allen kontroversen Themen aus. Über "Abortion" gibt es 15 Einträge, die vom Gedicht bis zum ausführlichen philosophischen Essay reichen. Der Text über "Spanking" (das Verhauen des Hinterteils, was in den USA gerne zur "Disziplinierung" von Kindern praktiziert wird, in einigen Bundesstaaten auch noch in Schulen) besteht dagegen aus zwei Benutzereinträgen, von denen der erste Spanking deutlich befürwortet (es gäbe weniger "verwöhnte Gören", wenn Schulen noch ordentlich den Kindern den Hintern versohlen würden; er selbst habe noch vernarbte Haut von einer seiner heftigsten Bestrafungen) und der andere das Thema Kinderbestrafung nur kurz behandelt und sich dann ausführlich über Spanking als Praxis unter Sado-Masochisten auslässt.
Viele Noder tragen in E2 ihre Hausaufgaben ein, so dass man mitunter komplette Essays mit Fußnoten findet (Beispiel: Frankenstein). Die meisten E2-Artikel behandeln jedoch nur einen Teil des jeweiligen Themas und überlassen es anderen Autoren, den Rest zu ergänzen.
Everything but an encyclopedia
Während bei Wikipedia die NPOV-Doktrin (vgl.
![]() Alle gegen Brockhaus) dazu führt, dass unterschiedliche Meinungen zu einem Artikel vereint werden und ein Text nicht den Schwerpunkt auf einen bloßen Teilaspekt eines Themas legen darf, gibt es bei E2 kein Neutralitätsgebot. Zweifellos haben die "Noder" Spaß am Schreiben, ob für den Leser aber etwas Brauchbares übrig bleibt, ist von Text zu Text unterschiedlich.
Alle gegen Brockhaus) dazu führt, dass unterschiedliche Meinungen zu einem Artikel vereint werden und ein Text nicht den Schwerpunkt auf einen bloßen Teilaspekt eines Themas legen darf, gibt es bei E2 kein Neutralitätsgebot. Zweifellos haben die "Noder" Spaß am Schreiben, ob für den Leser aber etwas Brauchbares übrig bleibt, ist von Text zu Text unterschiedlich.
E2 wird niemals eine Enzyklopädie sein, sondern stets nur eine Sammlung von unterschiedlichen Informations-Häppchen über bestimmte Themen. Einzelne Texte mögen es wert sein, referenziert zu werden - sicherlich ist E2 eine gute Quelle für TV-Episodenlisten, Technik-Terminologie und dergleichen. Und wer an Lyrik und Prosa interessiert ist, findet dort täglich neue Inspiration. Als Community ist E2 nur begrenzt zu verstehen, da Diskussionen innerhalb der Nodes rigoros unterbunden werden. Sogar im Chat taucht ab und zu der "Everything Death Borg" auf, der Benutzer rausschmeißt, wenn sie nach Meinung eines der E2-Götter etwas Unangemessenes gesagt haben. Das kann schon einfache Kritik an E2 selbst sein oder die Bitte, einen bestimmten Node anzuschauen.
Das System mit seinen zahlreichen Ebenen, Räumen und Machtstrukturen erinnert stark an Slashdot selbst, wo mit massivsten Moderations-Maßnahmen, Filtern und Bewertungssystemen gegen Trolle und andere unerwünschte Gäste gekämpft wird. Die Macher verstehen sich als Autorität, deren Regeln Folge geleistet werden muss - sonst folgen Konsequenzen. Während bei Wikipedia eine produktive Anarchie "herrscht" und lediglich ab und zu Eigner Jimbo Wales eine Entscheidung verkündet, gibt es bei E2 täglich willkürliche Löschungen, Beförderungen, Herabsetzungen und Drohungen. Alles dreht sich um den Einsatz und den Erwerb von Macht über andere Nutzer. Wer nicht genügend Write-Ups produziert, hat weniger Privilegien und verdient weniger Respekt.
Trotz der Bewertungen geht Quantität vor Qualität. Erst im März 2002 wurde ein komplexes System namens Honor Roll eingeführt, das es Benutzern mit Artikeln sehr hoher Bewertung erlaubt, auch mit weniger Write-Ups zur nächsten Stufe aufzusteigen. Doch lange Artikel mit vielen Fakten und Quellenangaben genießen nicht unbedingt eine hohe Reputation. Es ist zwar nicht möglich, ohne selbst abzustimmen, die Bewertung eines Artikels einzusehen; man kann sich jedoch die Artikel eines einzelnen Benutzers nach Bewertung sortiert anzeigen. In vielen Fällen sind das humorvolle und emotionale Texte, ungewöhnliche Fakten und Anleitungen wie How to win a knife fight. Und selbst Biographien oder beschreibende Texte sind oft nicht enzyklopädisch, sondern streng subjektiv gefasst. Was bei Wikipedia als Patzer gilt - Einschübe wie "bin mir nicht sicher" - ist bei Everything2 die Norm.
Klar: Würde der große Enzyklopädist Denis Diderot heute leben, würde er die Wikipedia als Volksenzyklopädie dem chaotischen Datenhaufen von Everything2 vorziehen. Doch sein Traumtagebuch würde er dort nicht führen können.
Auntie und die Anhalter
"Weit draußen in den unerforschten Einöden eines total aus der Mode gekommenen Ausläufers des westlichen Spiralarms der Galaxis leuchtet unbeachtet eine kleine gelbe Sonne. Um sie kreist in einer Entfernung von ungefähr achtundneunzig Millionen Meilen ein absolut unbedeutender, kleiner blaugrüner Planet, dessen vom Affen stammende Bioformen so erstaunlich primitiv sind, dass sie Digitaluhren noch immer für eine unwahrscheinlich tolle Erfindung halten."
So beginnt das Kultbuch "Per Anhalter durch die Galaxis" des britischen Autors Douglas Adams, erstes in einer Serie von fünf. Adams, der im Mai 2001 im Alter von nur 49 Jahren an einem Herzinfarkt verstarb, hatte schon lange vor Wikipedia die Vision einer offenen, von Nutzern verfassten Enzyklopädie.
|
In seiner Buchserie ist "Per Anhalter durch die Galaxis" auch der Titel einer Mischung aus Lexikon und Lifestyle-Magazin, das über die besten Drinks im Universum ebenso informiert wie über beinahe alle Planeten und ihre Bewohner (der Eintrag über die Erde begnügt sich mit den zwei Worten "größtenteils harmlos"). Doch der größte Vorteil des "Anhalters" ist der auf dem E-Book in großer, freundlicher Schrift aufgedruckte Text "Keine Panik". Dieser Schriftzug ziert auch die Startseite von H2G2. H2G2 steht für "Hitchhiker's Guide to the Galaxy" (zweimal H, zweimal G), der englische Originaltitel der Serie. Realisiert wurde die Website von Adams' Firma "The Digital Village"; aus Kostengründen wurde sie noch vor Adams' Tod im Februar 2001 von der BBC übernommen, die sich damit einen Image-Zugewinn erhoffte. "Auntie" BBC hatte in den 1970ern schon die Radioserie, auf der Adams' Bücher beruhen, finanziert.
Wie bei Everything2 muss man sich auch bei H2G2 zunächst registrieren, wenn man mitschreiben möchte. Dabei muss man die BBC House Rules akzeptieren, in denen unter anderem festgelegt ist, dass Englisch die einzige erlaubte Sprache ist. Artikel werden entweder als einfacher Text verfasst (wobei es einige wenige Formatierungs-Tricks für Links und dergleichen gibt) oder in der auf XML basierenden GuideML-Syntax.
Unterschieden wird bei H2G2 zwischen der offenen und der redigierten "Guide". Um in der offenen Version zu bleiben, muss ein Artikel nur der Hausordnung genügen, die redigierte Version ist dagegen strengen redaktionellen Kontrollen unterworfen. Artikel, die diese Qualitätskontrolle durchlaufen haben, werden auf der Hauptseite von H2G2 hervorgehoben und im Kategorienverzeichnis aufgelistet. Dazu müssen sie zunächst von anderen Autoren in einem Peer-Review-Prozess kommentiert und beurteilt werden, anschließend kümmern sich sogenannte "Sub-Editors", unbezahlte Freiwillige, darum, den Artikel nachzubearbeiten, die besten Einträge werden schließlich von "Scouts" an das H2G2-Team weiterempfohlen, das ggf. letzte Korrekturen vornimmt und den Artikel dann in die redigierte Version der "Guide" aufnimmt.
Jeder registrierte Leser kann Artikel für die Peer-Review-Phase vorschlagen, so dass es einen stetigen Fluss von Artikeln aus dem offenen Bereich in die redigierte Fassung gibt. Artikel, die alle Phasen durchlaufen haben, können jedoch von ihren Autoren nur noch schwer aktualisiert werden, was einer der Hauptkritikpunkte am derzeitigen System ist.
Ansonsten funktioniert H2G2 erstaunlich gut. Der offene Bereich erinnert ein wenig an Everything2; einzelne Artikel sind aber deutlich weniger intensiv verlinkt und häufig sogar völlig linkfrei. Die Qualitätskontrolle funktioniert dagegen wesentlich besser als bei E2, die in drei Hauptkategorien ("Life", "The Universe", "Everything", nach dem Titel des dritten Teils der Buchreihe) und zahlreichen Unterkategorien angeordneten redigierten Artikel sind meist von mittlerer Länge und von einheitlich hoher Qualität. Der Stil ist nicht unbedingt enzyklopädisch, sondern wie beim Romanvorbild häufig eher locker und humorvoll; zu Beginn des Projekts wollte jeder gerne wie Douglas Adams schreiben, doch mittlerweile hat sich ein etwas seriöserer Stil etabliert. Über 5.000 Einträge finden sich bereits in der redigierten Guide, was angesichts der starken Qualitätskontrolle ein recht stattliches Ergebnis ist.
Wie sieht es mit einzelnen Artikeln aus? Der redigierte H2G2-Artikel über Homöopathie ist eindeutig "A Sceptical View" betitelt und hinterfragt die Praxis in etwa 24000 Zeichen ausführlich. Der entsprechende Wikipedia-Text ist etwa genauso lang, vertritt aber den gewohnten neutralen Standpunkt, was in diesem Fall vielleicht nicht unbedingt vorzuziehen ist.
Viele Artikel in H2G2 sind aber tatsächlich eher Reiseführer-Material; in der Kategorie London findet man z.B. Reisen in London, Billige Haarschnitte in London, Cockney Rhyming Slang, Der ultimative Führer für den Londoner Untergrund usw. Dafür gibt es weit weniger typische Enzyklopädie-Artikel, so z.B. nur uneditierte Texte über Judaismus und George Bush, letzterer lautet zur Zeit so: "I'd hate to be called George Bush, it's like being called George Muff, George Fuzz or George Slice of Hairy Pie." Nonsens dieser Art würde natürlich nie den Weg in die redigierte Fassung finden.
H2G2 ist eine interessante Sammlung von Lifestyle-Artikeln und Texten über ungewöhnliche Themen, aber noch keine allgemeine Enzyklopädie. Außerdem ist es auch und vor allem eine Community: Jedem Artikel ist ein Diskussionsforum angefügt, daneben gibt es noch offene Foren zu diversen Themen und sogar die kleine Community-Zeitschrift The Post. Auch in dieser Hinsicht unterscheidet sich H2G2 von Wikipedia, wo Diskussionen meist spröde und sachbezogen sind.
Als Projekt unter der Schirmherrschaft der BBC ist H2G2 auch deren redaktioneller Kontrolle unterworfen. So wurden zum Beispiel während der britischen Parlamentswahl 2001 "heavy politics" in Kommentaren strikt untersagt, bestimmte Benutzernamen wie "OBL" (Osama Bin Laden) während des Afghanistan-Kriegs verboten, Diskussionen zu "problematischen" Themen wie dem Kinderporno-Skandal um Peter Townshend zensiert und Kommentare und Artikel über den Irak-Krieg komplett gelöscht (siehe H2G2 Announcements, wo sich die entsprechende Ankündigung derzeit noch findet). Erst am 24. April wurde die Regel aufgehoben, und bis heute findet sich kein Artikel über den Krieg in der redigierten "Guide". Offenbar möchte die BBC nicht mit politisch zu brisanten Texten assoziiert sein, was das Projekt für seriöse enzyklopädische Arbeit wenig brauchbar macht.
Nicht zuletzt solche Zensurmaßnahmen sind es, die viele ehemalige Fans zu Wikipedia treiben. So z.B. Martin Harper, der einen eigenen Guide for H2G2 Researchers geschrieben hat. Wer es über Monate nicht geschafft hat, seinen H2G2-Artikel zu aktualisieren, dürfte von der Schnelligkeit des Wiki-Prinzips beeindruckt sein.
Störend fällt bei H2G2 eine generelle Trägheit der Site auf. Das liegt zum einen am unnötig komplexen Layout, zum anderen an der sehr langsamen Volltextsuche. Mit Performance-Problemen haben fast alle Projekte dieser Art zu tun: Da praktisch alle Seiten dynamisch generiert werden und sich häufig ändern, sind die Software- und Hardware-Anforderungen nicht zu unterschätzen.
Fazit
Wikipedia ist und bleibt das interessanteste Projekt in der Kategorie "kollaboratives Schreiben". Weder H2G2 noch Everything2 sind "Open Content" - Einträge gehören den Autoren und dürfen außerhalb dieser Systeme ohne explizite Erlaubnis nicht weiter verwendet werden. Wenn BBC H2G2 einstellt oder damit anfängt, rigoros Einträge zu löschen, gibt es für die "Researcher" keine Ausweichplattform, kein Datenpaket zum Download, das es ihnen erlauben würde, ihren eigenen Ableger ins Leben zu rufen. Bei Everything2 ist zwar die Software frei verfügbar, aber für die Inhalte gilt das gleiche. Jeder kann dagegen den gesamten Text aller Revisionen der Wikipedia-Artikel herunterladen und für eigene Zwecke weiterverwenden.
Abgesehen davon überzeugt das Prinzip des gemeinsamen Bearbeitens - in der Tendenz sind Wikipedia-Artikel ausgeglichener und stilistisch einheitlicher als solche in H2G2 (nur redaktionelle Nachbearbeitung) und Everything2 (keinerlei Bearbeitung außer durch den Autor selbst). Redigierte H2G2-Texte haben dafür den Stempel der Autorität - ob dieser Stempel verdient ist, sei dahingestellt, denn die "Sub-Editoren", die einen Text nachbearbeiten, werden mehr oder weniger zufällig zugeordnet und verstehen oft nichts von dem jeweiligen Thema, es sind eher Korrekturleser als Faktenprüfer.
Langfristig kann man hoffen, dass hochwertigeres Material aus E2 und H2G2 von den jeweiligen Autoren nach Wikipedia portiert wird, was bereits zu einem gewissen Grad geschieht: Nutzer beider Communities wandern zur freien Enzyklopädie ab. Spin-Off-Projekte wie Disinfopedia dagegen haben von Anfang an eine Open-Content-Lizenz gewählt und ermöglichen so den freien Datenaustausch.
Insgesamt ist es beeindruckend, welche Menge an teilweise beeindruckend nützlichen Inhalten von Freiwilligen kostenlos in die verschiedenen Wissensdatenbanken eingespeist wird. "Das Web ist ein Werkzeug, das es denjenigen, die ein Leben haben, erlaubt, von der Arbeit derjenigen, die keines haben, zu profitieren", schreibt Geoffrey Nunberg zynisch in der New York Times. Tatsächlich sind Online-Communities, ob Rollenspiel oder Wissensdatenbank, oftmals sehr zeitintensive Hobbies. Ob es aber im Sinne eines erfüllten Lebens ergiebiger ist, Wissen in eine freie Datenbank einzutragen oder sich einen neuen Hollywood-Film im Kino anzuschauen, sei dahingestellt. Aus Nunbergs Zitat spricht die klassische Verächtlichkeit gegenüber den "Geeks", die sich auf merkwürdigen Websites tummeln, statt "normalen" Hobbies nachzugehen. Wie beim Phänomen der Weblogs ist es aber vielleicht nur eine Frage der Zeit, bis auch Oma Meier ihre Strickmuster in einer offenen Wissensdatenbank einträgt.
Diesen Artikel bearbeiten
Tanz der Gehirne: Teil 4
Innerhalb von Minuten wird bei Wikipedia der gleiche Artikel editiert von einem Studenten aus Tokyo, einer Einzelhändlerin aus Köln, einem Gärtner aus Essex. Würde man die Aktivitäten sichtbar machen, so sähe Wikipedia selbst aus wie ein gigantisches neuronales Netz, in dem ständig die Synapsen unter Feuer stehen. Dieses Phänomen ist so erstaunlich, dass die Selbstverständlichkeit, mit der es hingenommen wird, fast schon erschreckt. Doch die zugrundeliegende Idee ist älter, als man vielleicht zunächst annimmt. Die Entwicklung hin zu einer noch massiveren Gleichzeitigkeit, einer noch intensiveren Vernetzung unserer Kultur scheint unvermeidlich.
Es war nach dem Sieg der Alliierten gegen die Nazis und vor dem Abwurf der Atombomben auf Hiroshima und Nagasaki.
Als Direktor des dem Weißen Haus unterstellten Office of Scientific Research and Development und führender wissenschaftlicher Berater des US-Präsidenten hatte sich Vannevar Bush für die Entwicklung von Nuklearwaffen eingesetzt, um Hitler zuvorzukommen und den Krieg zu einem schnellen Ende zu führen. Nach dem Tod von 55 Millionen Menschen durch Krieg und Holocaust und vor dem Abwurf von "Fat Man" und "Little Boy" machte sich Bush Gedanken darüber, womit sich Wissenschaftler beschäftigen könnten, wenn mit all dem kriegerischen Unsinn endlich Schluss sei. Obwohl er den bevorstehenden Kalten Krieg und das nukleare Wettrüsten vorausahnte, stand ihm der Sinn nach friedlicheren Visionen.
So veröffentlichte er im Juli 1945 im amerikanischen Monatsmagazin The Atlantic Monthly ein Essay mit dem Titel As We May Think ("Wie wir denken mögen"). Darin denkt Bush darüber nach, wie Wissenschaftler in Zukunft mit dem "wachsenden Berg an Forschung" umgehen können.
Der Forscher gerät ins Schwanken im Angesicht der Ergebnisse und Schlussfolgerungen von Tausenden anderer Arbeiter - Schlussfolgerungen, die er aus Zeitgründen nicht erfassen und sich noch weniger merken kann, während sie sich anhäufen. Trotzdem wird Spezialisierung immer notwendiger für den Fortschritt, und Bemühungen die Disziplinen zu überbrücken sind entsprechend oberflächlich.
Angesichts der Informationsexplosion würde es immer schwieriger, die Spreu vom Weizen zu trennen:
"Mendels Idee der Gesetze der Genetik war der Welt für eine Generation verloren gegangen, weil seine Veröffentlichung nicht die wenigen erreichte, die in der Lage gewesen wären, sie zu verstehen und zu erweitern; solche Katastrophen wiederholen sich zweifellos um uns herum, wenn wahrhaft wichtige Errungenschaften in der Masse des Folgenlosen verschütt gehen."
Und so spekulierte Bush über die zukünftigen Möglichkeiten vorhandener Technik. Besonders der Mikrofilm hatte es ihm angetan. Wenn man von bisherigen Entwicklungen extrapoliere, könne man davon ausgehen, dass sich das Wissen der Menschheit schon bald miniaturisieren ließe:
Die Encyclopaedia Britannica ließe sich auf die Größe einer Streichholzschachtel reduzieren. Eine Bibliothek mit einer Million Büchern könnte in einen Schreibtisch passen.
Weit von der Realität entfernt ist das nicht. Mikrofilme und Mikrofiches erlauben tatsächlich die hochkompakte Speicherung von Informationen - ein vollständiges Buch passt auf eine dünne Plastikfolie, in einem Schrank lassen sich Zehntausende Volumen speichern. Ohne Konkurrenz durch digitale Medien würde wohl jeder schon einmal Bekanntschaft mit den robusten, wenn auch etwas unhandlichen Betrachtungsgeräten gemacht haben. Diese Art der Konservierung wird auch heute noch für zahlreiche historische Sammlungen eingesetzt.
Vannevar Bush war sich durchaus der Entwicklung von Computern bewusst, hatte er doch schon 1927 einen Analogrechner auf der Basis von Charles Babbages Differenzmaschine konstruiert.
"Die fortgeschrittenen arithmetischen Maschinen werden elektrischer Natur sein und hundertmal so schnell wie derzeit, oder mehr. Sie werden weitaus vielseitiger sein als die derzeitigen kommerziellen Maschinen, so dass sie sich für eine weite Zahl von Operationen nutzen lassen. Sie werden mit Kontrollkarten oder Filmen gesteuert werden, sie werden ihre Daten selbst auswählen und gemäß der eingefügten Instruktionen manipulieren. Sie werden komplexe Berechnungen bei außerordentlicher Geschwindigkeit durchführen und ihre Ergebnisse in einer für Nachbearbeitung und Verbreitung geeigneten Form festhalten. ... Es wird immer einiges zu berechnen geben bei den einzelnen Angelegenheiten von Millionen Menschen, die komplizierte Dinge tun."
Filmforscher
Doch für den zukünftigen Forscher sollte nach Bushs Vision die Film- und Tontechnik im Vordergrund stehen. Mini-Kameras sollten alles festhalten, Maschinen sprachgesteuert werden, womöglich mit Hilfe einer speziellen mechanisierten Lautsprache. Das mag albern klingen, ist aber nicht so weit von den künstlichen Schreibarten entfernt, die manche stiftgesteuerte Rechner ihren Nutzern abverlangen. Doch gab es nicht schon genug Informationen? "Soweit sind wir schlechter dran als vorher", notierte Bush. Das Grundproblem sei das der Selektion von Informationen - aber auch hier ließe sich mit fortgeschrittener Technik einiges machen.
|
Er kritisierte die Ineffizienz klassischer Speichersysteme, die es erforderlich machten, numerische und alphabetische Indizes, Themenkatalogisierungen und dergleichen immer wieder aufs Neue zu durchsuchen.
Der menschliche Verstand funktioniert nicht auf diese Weise. Er operiert mit Assoziationen. Hat er einen Begriff erfasst, knipst er sofort zum nächsten, der durch die Assoziation der Gedanken nahe liegt, gemäß einem komplexen Gewebe von Pfaden, die durch die Gehirnzellen getragen werden. (...) Die Prozessgeschwindigkeit, die Komplexität der Pfade, die Detailgenauigkeit geistiger Bilder ist ehrfurchtgebietend vor allem anderen in der Natur.
Und so sollte schließlich die Synthese verschiedener Technologien - fortgeschrittener Mechanik und Steuersysteme, Mikrofilmspeicherung, Spracheingabe - zu einem assoziativ arbeitenden System führen, das Bush "Memex" nannte, eine Art Terminal, an dem der Nutzer jede beliebige von Millionen Buchseiten betrachten kann; zwei Seiten könnten über Codes miteinander verknüpft werden, und so könne der Nutzer Pfade von einer Seite zur nächsten weben. Mittels Fototechnik sollten die Seiten auch mit Bemerkungen versehbar sein. Einige Werke wie Enzyklopädien würden mit vorprogrammierten Pfaden ausgeliefert werden, so dass der Nutzer bestimmte zusammenhängende Themen problemlos erkunden kann. Aber Pfade würden auch unter den Nutzern ausgetauscht werden, und professionelle "Pfadfinder" würden sich im Informationsdickicht auf die Suche nach besonders wertvollen Seiten machen.
So erinnert Memex letztlich an Hypertext, doch wer das System schlicht als einen Vorläufer des Web betrachtet, denkt nicht weit genug. Denn das Web wird von den meisten Nutzern nur passiv konsumiert. Innerhalb von Memex sollte der Nutzer aber auch stets Inhalte schaffen - Bewertungen, Verknüpfungen, Kommentare.
Aber nicht den Mikrofilmen sollte die Zukunft gehören, sondern den Transistoren, Röhrenmonitoren und Festplatten. Mikrofilme und Fiches sind zwar wunderbar kompakt (so kompakt, dass sie leicht verloren gehen), aber es sind eben keine manipulierbaren Daten, und schon damals stand das Urheberrecht der Streichholz-Schachtel-Britannica im Wege. Computer wurden trotzdem lange nur als Rechenknechte angesehen - bis zur Universalmaschine und zum dadurch ermöglichten weltweiten Kommunikationsnetz war es noch ein weiter Weg.
Der ewige Pionier
Einer der diesen Weg ahnte und bahnte ist Douglas Engelbart. 1945 war Engelbart auf den Philippinen als Radartechniker stationiert - und fand in einer Bibliothek des Roten Kreuzes, in einer Hütte auf Stelzen, einen Nachdruck des Artikels "As We May Think" im Life Magazine. Nach einigen Jahren als Elektroingenieur im renommierten Ames Research Center des NASA-Vorläufers NACA studierte er an der Berkeley-Universität, wo man zwar schon über Computer forschen konnte, jedoch noch keinen hatte.
1957 trat er dem Stanford Research Institute (SRI) bei und dachte mehr und mehr darüber nach, wie er als Ingenieur einen Beitrag zur weiteren Entwicklung der Menschheit leisten könnte. 1962 schließlich hielt er seine Visionen in dem Papier Augmenting Human Intellect: A Conceptual Framework fest. Die "Vergrößerung des menschlichen Intellekts" sei notwendig, da die Komplexität menschlicher Probleme in allen Bereichen exponentiell ansteige. "Eines der unmittelbar vielversprechendsten Werkzeuge", so Engelbart, "ist der Computer."
Unter direkter Bezugnahme auf Vannevar Bushs Arbeit nannte Engelbart verschiedene Charakteristika, die ein computerbbasiertes System zur Informationsorganisation aufweisen müsse. Er beschrieb ein bildschirmbasiertes Textverarbeitungs-System mit Hyperlink-Funktionalität, das über Tastatur und Lichtstift gesteuert werden konnte. Verweise auf andere Dokumente sollten an jeder Stelle jederzeit eingefügt werden können, die Textverarbeitung sollte über weitreichende Makro-Techniken verfügen, um Worte in Kurzform eingeben zu können - eine Funktion, die in den meisten heutigen Anwendungen nur in Form rudimentärer Auto-Vervollständigung existiert. Auch das Nachschlagen beliebiger Worte im Thesaurus oder Wörterbuch sollte möglich sein. Texte sollten auf einfachste Weise strukturiert und kategorisiert werden können.
Engelbart bekam die Finanzierung für ein Projekt unter seiner Leitung, das "Augmentation Research Center". In den nächsten Jahren entwickelte er mit einem 17 Mann starken kreativen Team die Hardware und Software, um das bisher rein fiktive System Wirklichkeit werden zu lassen. Fast alles musste von Grund auf neu erfunden werden. Im Dezember 1968 war es schließlich soweit. Auf der Joint Computer Conference in San Francisco, einem regelmäßigen Treffen von EDV-Enthusiasten, wurde das von Engelbart und seinem Team entwickelte "Online-System" (NLS) live vorgeführt. Dazu wurde ein großer Projektionsschirm verwendet, der abwechselnd oder gleichzeitig als "Split Screen" sowohl Engelbart mit Headset als auch den Bildschirminhalt des Testsystems zeigte. Der junge, charismatische Engelbart, der ohne große Schwierigkeiten im System navigierte und dabei Erklärungen lieferte, wirkte auf die rund 1000 Zuschauer wohl wie ein Besucher aus der Zukunft. Natürlich gab es auch den ersten Live-Absturz, aber der Neustart des NLS dauerte nur wenige Sekundenbruchteile und wurde wohl von den meisten Zuschauern gar nicht bemerkt.
Engelbart führte Dinge vor, die die Welt noch nicht gesehen hatte. Das von ihm konzipierte Textverarbeitungs-System war nun funktionsfähig. Es erlaubte das Adressieren und Verlinken von Dokumenten. Inhalte konnten dynamisch in sogenannten "Views" angezeigt werden: Unerwünschte Zeilen ließen sich "wegfalten", Listen mit Nummerierung versehen, Texte nach bestimmten Kategorien filtern usw. Auch klickbare Diagramme mit Links ließen sich schnell erstellen.
Viele dieser Funktionen sind in heutigen Textverarbeitungen nicht vorhanden, und selbst das einfache Einfalten von Absätzen ist in den meisten Editoren nicht möglich. Gesteuert wurde NLS mit einem Keyboard, einem Einhand-Keyset namens "Chord" und der ersten Maus, ein noch recht klobiges Holzgehäuse auf Rädern. Die Idee hinter der Maus stammte von Engelbart selbst, der auch ein Patent darauf erhielt, das jedoch nicht gegen Nachahmer zum Einsatz kam.
Schließlich demonstrierte Engelbart, wie zwei Nutzer in einer Telekonferenz (mit Video) am gleichen Text arbeiten können. Diese Art der Echtzeit-Kollaboration in Teams war ein Schlüsselelement seiner "Augment"-Strategie. Da huschten plötzlich zwei Mauszeiger gleichzeitig über den Schirm, einer von Engelbart, der andere von seinem Kollegen Bill Paxton, der ein paar Kilometer entfernt zugeschaltet war. "Mein Käfer ist stärker als Deiner", verkündete Engelbart grinsend und schob seinen Mauszeiger drohend in Richtung des zweiten. Neben dem gleichzeitigen Editieren wurde auch ein "Whiteboard" demonstriert, an dem beide Nutzer Zeichnungen erstellen konnten. Die Präsentation, die komplett im Netz ist, gilt heute als "Mutter aller Demos". Sie endete, wie sollte es anders sein, mit stehenden Ovationen.
Engelbarts ARC-Labor war die zweite Maschine im ARPANET, dem Vorläufer des Internet. Doch er war seiner Zeit weit voraus. Seine komplexen Ideen fanden in der Industrie nur wenig Anklang, und einfachere Ansätze wie Unix-Terminals setzten sich durch. Nach zahlreichen Abweisungen und weiteren Entwicklungsgenerationen seiner Software verlor Engelbart 1989 sein Labor bei McDonnell Douglas Corp., die keinen Praxiswert seiner Forschungen erkennen konnten.
Zusammen mit seiner Tochter gründete er das Bootstrap-Institut, das sich weiterhin für die Verwirklichung einiger Augment-Ideen stark macht und mittlerweile eine Schar loyaler Anhänger hat. Zu den Bootstrap-Ideen gehören Back-Links (also automatische Rückverweise auf auf diejenigen Seiten, die auf eine Seite zeigen), exakte Link-Adressierung (z.B. auf ein bestimmtes Wort in einem Absatz), indirekte Links, die auf den gerade aktuellen Link an einer bestimmten Position zeigen sowie implizite Links, also z.B. automatische erzeugte Links auf Wörterbuch- oder Enzyklopädie-Artikel. Engelbarts Institut entwickelte zur Realisierung dieser Konzepte das Open Hypertext System, einen offenen Standard. Bittere Ironie: Die OHS-Mailing-Liste ist von Spam-Nachrichten überflutet.
Tim, der Weber
Die Zukunft gehörte nicht den Visionen von Douglas Engelbart oder den ähnlich weitreichenden Xanadu-Ideen des Ted Nelson. Der Erfinder des WWW, wie wir es kennen, ist natürlich der Brite Tim Berners-Lee, der 1989 dem CERN-Labor nahe Genf das Papier Information Management: A Proposal einreichte. Basierend auf seinen früheren Arbeiten an einfachen Hypertext-Systemen schlug er ein dezentrales Seiten-Netz zur Informationsorganisation vor. Nach dem üblichen Streit um Forschungsgelder bekam er schließlich 1990 das Okay und entwickelte auf einer NeXT-Maschine den ersten Browser, der nun schon den Namen WorldWideWeb trug.
|
Doch der erste Browser war gleichzeitig auch ein Editor. Während er Dateien auf externen Rechnern wie gewohnt anzeigte, konnten lokale Dateien gleichzeitig auch bearbeitet werden, ohne dass der Nutzer irgendeinen Texteditor aufrufen musste - sie waren sofort im gleichen Programm veränderbar. Dank der leistungsfähigen NeXT-Benutzeroberfläche war WorldWideWeb ein WYSIWYG-Programm. "What You See Is What You Get", Änderungen in Schriftgröße und Stil wurden also sofort sichtbar, das Bearbeiten von HTML-Code war nicht erforderlich. Der Leser konnte sogar für verschiedene Seiten unterschiedliche Stilvorlagen verwenden und z.B. die Anzeigegröße einzelner Überschriften ändern.
Es sollte Jahre dauern, bis derart mächtige Software in die Hand von Normalsterblichen kam. Das lag nicht zuletzt an der softwaremäßig unterentwickelten DOS/Windows-PC-Plattform, für die derartige Anwendungen nur mit sehr hohem Aufwand entwickelt werden konnten. Zunächst erreichte das Web die meisten Nutzer als rein passives Erlebnis, ganz anders als von Berners-Lee geplant. Die Erstellung von HTML-Seiten blieb lange Zeit die Domäne von erfahrenen Computernutzern: Neben HTML-Kenntnissen war auch Serverplatz vonnöten. Studenten an Unis konnten Webseiten relativ leicht einrichten, indem sie einfach eine index.html-Datei in ihrem Benutzerverzeichnis anlegten. Für Nutzer von außerhalb blieb nur das Betteln nach Webspace oder die kostenpflichtige Miete. Mittlerweile gibt es kostenlosen Webspace an jeder virtuellen Ecke.
Das Bearbeiten von Inhalten durch Dritte war natürlich noch komplizierter. Dafür fehlten dem WWW auch Eigenschaften, die in theoretischen Modellen wie Xanadu längst vorgesehen waren, z.B. die "ewige Revisionsgeschichte" aller Seiten. Mit einigen technischen Änderungen hätte das Web schon von Anfang an wie Wikis funktionieren können - natürlich mit kontrollierbaren Zugriffsrechten. Doch die mangelnde Funktionalität der Browser und der Architektur selbst machte eine Notlösung wie Wikis erforderlich, die ja schon 1995 auf den Plan kamen (siehe Teil 1). Einzig allein das von Berners-Lee geleitete W3C hält die Browser-Editor-Idee noch pro forma aufrecht: Der experimentelle Browser Amaya erinnert an WorldWideWeb, ist aber so instabil wie das Adjektiv "experimentell" vermuten lässt.
Veni vidi wiki?
WYSIWYG-Editoren fürs Web sind heute gang und gäbe. Der HTML-Editor FrontPage ist Bestandteil von Microsoft Office, die Gratis-Dreingabe "Frontpage Express" wurde dagegen mysteriöserweise eingestellt. Mozilla bzw. Netscape verfügt über den leistungsfähigen "Composer", und Webdesigner arbeiten mit ausgereiften Werkzeugen wie Macromedias Dreamweaver. Echte Hacker dagegen editieren natürlich den HTML-Quelltext von Hand, wobei auch hier professionelle Texteditoren die Arbeit erleichtern. Die Trennung zwischen Browser und Editor bleibt stets gewahrt.
Von einem Web, in dem jeder die Worte des anderen korrigiert, sind wir noch weit entfernt. Wer veröffentlichen will, braucht Webspace, kollaboratives Arbeiten ist erst mit kostenpflichtigen Werkzeugen oder mit viel technischem Können möglich. So hatte sich das Doug Engelbart nicht vorgestellt: Statt den "kollektiven IQ" zu erhöhen, wächst mit dem Netz vor allem der Informationsmüllberg und begräbt wertvolle Ideen unter sich.
Wikis bilden dagegen die Antithese zur bunten aber letztlich inhaltsarmen Spielwiese. In nüchterner Verpackung versprechen sie meist kein WYSIWYG, sondern nur eine vereinfachte Syntax gegenüber HTML. Doch der Wikitext bietet auch Vorteile: Formatierungsfehler lassen sich schneller korrigieren, das Ergebnis entspricht fast immer den Erwartungen und funktioniert auf allen Plattformen gleichermaßen.
Wikis haben jedoch das Interesse nach leistungsfähigen Browser-Editoren neu entflammt. Die Browser-Hersteller und Drittlieferanten haben den Bedarf erkannt, auch angesichts der im kommerziellen Umfeld sehr verbreiteten Content-Management-Systeme, die nicht so offen sind wie Wikis, aber ähnliches leisten. Und so gibt es bereits die ersten WYSIWYG-Wikis. SeedWiki bietet zum Beispiel Gratis-Wikis an, die das sogenannte "ActiveEdit"-Control verwenden. Das ist ein ausführbares Windows-Program, das nur im Microsoft Internet Explorer funktioniert. IE-Nutzer können SeedWiki-Seiten damit bequem in WYSIWYG-Form editieren, allen anderen offenbart sich HTML-Code. Das liegt daran, dass ActiveEdit keinen Wiki-Text produziert, sondern HTML - so müssen Nutzer ohne Microsoft-Browser sich mit dem von anderen produzierten, teilweise sehr redundanten HTML-Code herumschlagen.
Jüngere Versionen des Mozilla-Browsers bringen dagegen ihren eigenen "Rich Text Editor" namens MIDAS mit. Der ist noch instabil und unvollständig, etabliert aber einen offenen Standard, dem andere Open-Source-Applikationen folgen können. Auch hier ist das Problem, dass die Rich-Text-Editoren HTML produzieren, was es schwierig macht, im gleichen Wiki WYSIWYG- und Plaintext-Bearbeitung zu ermöglichen.
Die prinzipielle Leistungsarmut browser-interner Texteditoren wirkt ebenfalls kontraproduktiv. Ein einfaches Texteditorfenster in Mozilla kann z.B. weder durchsucht noch gespeichert werden. Zu allem Überfluss scheitert der freie Browser unter Linux daran, Text aus der Zwischenablage einzufügen, der länger als 4000 Bytes ist. Das Problem ist seit Oktober 2000 bekannt und macht es unmöglich, effektiv mit externen Editoren zu arbeiten. Es erscheint bei so grundsätzlichen Problemen fast gewagt, über WYSIWYG-Wikis nachzudenken.
|
Währenddessen demonstriert der MacOS-Editor Hydra noch mutigere Funktionalität. Er erlaubt es mehreren Usern, gleichzeitig einen Text zu bearbeiten. Änderungen der jeweils am Text aktiven Nutzer werden unterschiedlich farblich hervorgehoben. Das Programm ist ein schönes Werbeprojekt für Apple, denn es nutzt dessen neue Netzwerktechnik Rendezvous, die ans Netz angeschlossene Rechner sofort erkennen und logisch konnektieren soll. Dokumente in einem solchen Netz sollen mit Hydra komfortabel in einer Arbeitsgruppe bearbeitet werden können. Doch als reine Mac-Technologie bleibt Hydra den meisten Nutzern vorenthalten.
|
Der GNU-Editor Emacs bietet in einer X-Window-Umgebung ähnliche Funktionalität, allerdings bei weitaus weniger Komfort. Bis sich die Wikis parallel bearbeiten lassen, wird wohl noch einige Zeit verstreichen.
Wann kommt der Wiki-Editor?
Aufgrund der notorischen Schwächen von browser-integrierten Lösungen scheint es nur eine Frage der Zeit zu sein, bis ein speziell für das Bearbeiten von Wikis zugeschnittener Editor entwickelt wird. Emacs erlaubt es im WikiMode, lokale Dateien im Wiki-Stil miteinander zu verknüpfen, hat aber nichts mit dem Editieren auf einem gemeinsam genutzten Wiki-Web am Hut.
Auf Wikipedia ist schon seit längerem eine Diskussion über einen dedizierten Wiki-Editor im Gange. Bisher gibt es immerhin schon einen "Offline-Reader" namens WINOR [http://meta.wikipedia.org/wiki/WINOR], mit dem sich der Inhalt der Wikipedia-Datenbank anzeigen lässt. Programmiert wurde er von Magnus Manske, der auch schon die Wikipedia-Software der zweiten Generation entwickelt hatte. Ein solches Leseprogramm ist nützlich, um Wikipedia und andere Wikis z.B. auf CD-ROM herauszugeben.
|
Es wäre begrüßenswert, wenn sich die verschiedenen Wikis auf einen Standard für die Text-Syntax verständigen könnten - tatsächlich wird es wohl darauf hinauslaufen, dass Wikipedia als größtes Wiki den Standard definiert. Ebenfalls nützlich für Programmierer von externen Editoren wäre der Export der Wiki-Funktionalität als Web-Service: Derzeit muss ein Wiki-Texteditor einen realen Benutzer simulieren und entsprechende Eingaben an den Server schicken, ändert sich die Benutzerschnittstelle nur leicht, funktioniert der Editor nicht mehr. Web Services z.B. auf XML-Basis kapseln nur die programmnotwendigen Daten in maschinenlesbarer Form und vereinfachen deshalb die Entwicklung erheblich.
Pfadfinder
Wikipedia ist ohne diese fortgeschrittenen Entwicklungen bereits sehr erfolgreich. Doch ein elementares Problem ist noch nicht gelöst: Wie soll ein Leser zwischen einem gerade mit völlig falschen Behaptungen übersäten Text und einem sorgfältig geprüften, im Wikipedia-Sinne "brillanten" Artikel unterscheiden? Wenn dem Leser letztlich die Faktenprüfung überlassen wird, unterscheiden sich Wikipedia-Seiten nicht von anderen Google-Treffern. Wikipedia selbst kann dann niemals eine hohe Reputation aufbauen, weil die Glaubwürdigkeit eines Artikels zu jedem Zeitpunkt in Frage steht.
Vannevar Bush hat mit seiner Idee der Pfadfinder, die hochwertige Informationen suchen und diese austauschen, bereits einen Lösungsweg aufgezeigt. Doch das elementare Problem der Informationsbewertung wird im Internet typischerweise völlig unterschätzt. Wie schon 1945 drohen wir in der Informationsmenge zu versinken. Da liegt es nahe, zurück ans sichere Ufer zu schwimmen, sprich, sich auf "glaubwürdige" Quellen wie Mainstream-Medien zu verlassen.
Für Enzyklopädien wie Britannica, Brockhaus und Encarta besteht deshalb scheinbar keine Gefahr: Sie können darauf verweisen, dass Wikipedia ja nur ein Haufen von Amateuren ist, deren Artikel keinerlei Qualitätskontrolle durchlaufen haben.
Tatsächlich haben sich die Wikipedianer bereits ausführlich Gedanken über ein Zertifizierungs-System gemacht. Der Meta-Artikel Wikipedia Approval Mechanism listet verschiedene Vorschläge der Vergangenheit auf. Wikipedia-Gründer Larry Sanger schlug vor, jeder Autor mit entsprechender fachlicher Qualifikation solle einen Artikel in seinem Gebiet zertifizieren können. Diese Experten würden wiederum von einem Team von Moderatoren ausgewählt oder abgelehnt. Ein zertifizierter Artikel würde dann entsprechend hervorgehoben.
Ein anarchistischer Vorschlag lautete, Nutzer sollten von ihnen geprüfte Artikel schlicht auf ihrer Benutzerseite auflisten. Damit wäre jeder Nutzer in der Lage, an der Prüfung von Texten teilzunehmen, und wer geprüfte Artikel lesen wolle, könne dies durch das Navigieren auf den Seiten der Nutzer, denen er vertraut, ohne Weiteres tun.
Letztlich wurde keiner dieser Vorschläge implementiert. Zu viele Fragen blieben unklar: Was passiert, nachdem ein zertifizierter Artikel erneut bearbeitet wurde? Wie werden die Experten ausgewählt? Eine Idee, die jedoch die reine Diskussionsphase verlassen hat, ist das von Sanger gestartete "Sifter"-Projekt. Sifter hat oder hatte das Ziel, eine Kopie von Wikipedia zu schaffen, die nur qualitätskontrolliert Artikel enthält. Auch hier würden wieder - nach unklaren Kriterien ausgewählte - Experten bestimmte Revisionen eines Artikels zertifizieren und diese dann per Knopfdruck in das Parallelprojekt kopieren. Nach Larry Sangers erneutem Ausscheiden aus dem Projekt ist es darum sehr still geworden.
Es zeigen sich bei der Problematik gewisse Parallelen zur Free-Software-Szene. Das Debian GNU/Linux-Projekt bietet über 8700 sogenannte "Pakete" mit vorkompilierter Software oder Dokumentation an. Es genügt die Auswahl des Paketnamens, und das Paket wird heruntergeladen und installiert. Abhängigkeiten, also z.B. notwendige Plug-Ins, Dokumentation und Programmbibliotheken, werden automatisch aufgelöst, d.h. nachinstalliert. Pakete werden von sogenannten "Maintainern" verwaltet und durchlaufen verschiedene Phasen. Wenn eine neue Version eines Pakets entwickelt wurde, landet sie im "experimental" Bereich, wenn der Entwickler sie für testfähig hält im "unstable"-Bereich, wenn das Paket auf allen Plattformen zumindest ohne kritische Fehler funktioniert gelangt es in den "testing"-Bereich, und zu einem gewissen Zeitpunkt, wenn das Debian-Projekt alle Jubeljahre eine neue Version von Debian GNU/Linux herausbringt, wird der gesamte "testing"-Bereich als "stable" erklärt.
Dieser Prozess ist relativ langwierig, stellt aber eine gleichbleibend hohe Qualität der Pakete sicher. In jeder Phase findet ein "Peer Review" durch andere Entwickler und Tester statt. Die jeweils aktuelle "stable"-Version enthält relativ alte Pakete, die dafür aber funktionieren. Kritische Sicherheitsfehler werden auch rückwirkend korrigiert, d.h. in veralteten Programmversionen - angesichts des verfügbaren Quellcodes kein Problem.
Wikipedia lässt sich am ehesten mit der "experimental"- oder "unstable"-Phase eines Debian-Projekts vergleichen. Wer Wikipedia in der "instabilen" Version benutzt, kann am Schöpfungsprozess teilnehmen und erhält stets die aktuellsten Informationen, muss aber auch mit Fehlern rechnen. Ein Projekt wie "Sifter" würde dagegen eine oder mehrere neue Phasen schaffen.
Expertokratie
Das Problem mit einer solchen Sichtweise ist natürlich, dass eine Artikelzertifizierung kein rein mechanischer Prozess wie die Überprüfung eines Paketes auf seine Lauffähigkeit hin ist. Ob der Artikel über Abtreibung oder die christlichen Verbindungen zum Nationalsozialismus hoher Qualität ist, hängt nicht zuletzt von der Meinung des jeweiligen Beurteilers ab. Verlässt sich Wikipedia hier ausschließlich auf Experten im Sinne des universitären Status, wird dies auch durch die Artikelauswahl reflektiert werden. Es entsteht eine Mainstream-Enzyklopädie, die alternative Ansichten in manchen Fällen bewusst verschweigt. Womöglich ändert der eine oder andere Experte sogar eine problematische Passage, kurz bevor er die neueste Revision des Artikels zertifiziert.
Würde ein amerikanischer Politikwissenschaftler einen Artikel über CIA-Gedankenkontrolle zertifizieren oder so lange als "zu spekulativ" zurückweisen, bis der Text sich von den diskutierten Vorgängen distanziert? Würde ein katholischer Historiker eine hagiographische Diskussion tolerieren, in der die Historizität aller Heiligen massiv in Frage gestellt wird? Vor solchen Szenarien haben viele der zu anarchistischen Tendenzen neigenden Wikipedia-Mitglieder Angst. "Ein Bewertungsmechanismus wurde schon von Anfang an vorgeschlagen, und obwohl alles darauf hindeutet, dass Wikipedia wunderbar funktioniert, wird es wohl in alle Ewigkeit so weitergehen", heißt es deshalb auch auf der oben erwähnten Seite.
Ein denkbarer Ansatz wäre es, dass sich Pfadfinder zu Gruppen (Pfadfindervereinen?) zusammenschließen, die jeweils nach unterschiedlichen Regeln arbeiten und nach unterschiedlichen Kriterien Mitglieder aufnehmen. Ein loser Zusammenschluss von Pedanten könnte auf die Suche nach Tipp- und Rechtschreibfehlern gehen, ein striktes Mathematiker-Konsortium jeden Beweis genauestens überprüfen, ein virtueller Gärtnerclub sich um die Einhaltung der Namenskonventionen bezüglich Nutzpflanzen kümmern. Jede dieser Gruppen könnte Revisionen eines Artikels zertifizieren - enthält ein Artikel zertifizierte Revisionen, würde dies sichtbar gemacht. Nutzer könnten auswählen, welchen Gruppen sie vertrauen und entsprechende Sichtpräferenzen definieren, wobei in die Standardeinstellungen sicher nur die eher konservativen Teams aufgenommen würden.
Auch hier bleiben Fragen offen. Sollte z.B. jede Gruppe akzeptiert werden, oder sollten eindeutig politisch motivierte Teams von der Zertifizierung ausgeschlossen werden? Wikipedia hat für fast alle Fragen des Nutzerverhaltens Regeln und Konventionen definiert, es wäre wohl nur eine Frage der Zeit, bis auch hier entsprechende Normen entstehen würden.
Mit Wikis lernen
Ob zertifiziert oder nicht, eine offene, prall mit Inhalten gefüllte Enzyklopädien, die offenkundig süchtig macht, mag ein guter Weg sein, Kinder und Jugendliche mit Informationen "anzufixen". Dem trockenen, meist didaktisch schwachen Unterricht steht im Wiki das autodidaktische Lernen und Entdecken gegenüber. Wer einen Artikel schreiben und damit ein Erfolgserlebnis erzielen möchte, muss sich Gedanken darüber machen, woher die Informationen kommen sollen. Einfaches "Copy & Paste" wird aus urheberrechtlichen Gründen gnadenlos rückgängig gemacht. Holprige Formulierungen werden dagegen oft schnell verbessert.
Viele Lehrer und Professoren haben bereits Schüler und Studenten auf die Wikipedia losgelassen. Dies äußert sich meist in einem sprunghaften Anstieg experimenteller Edits, die aber in der Regel nicht bösartig sind. Ein Experiment, das im Internet transkribiert wurde, führte Hanjo Iwanowitsch durch. Er ist Lehrer an der Beruflichen Schule des Kreises Ostholstein in Eutin und wollte einige Buchhandel-Azubis auf ihre Wiki-Fähigkeiten hin testen. "Ihre Aufgabe war es, ihr in den vorhergegangenen vier Schulwochen erworbenes Wissen über die Buchherstellung in Wikipedia-Artikel umzusetzen." Die entstandenen Artikel sind zwar meist kurz aber durchaus lesbar, einige Gruppen wie das "Team Einband" haben sich sogar Mühe gegeben, ausführliche Artikel zu schreiben. "Mit der Zeit arbeite man wie im Rausch", zitiert Iwanowitsch seine Schüler.
Die Seite
Wiki in der Schule beschäftigt sich dagegen allgemein mit dem Einsatz von Wikis als Lern- und Lehrhilfe und gibt zahlreiche Praxistipps. Als Wiki-Software wird hier TWiki favorisiert, das jedoch die klassischen CamelCase-Links einsetzt (siehe
![]() Das Wiki-Prinzip).
Das Wiki-Prinzip).
Eine Sorge, die solche Experimente begleitet, ist die Offenheit der Wikis, die nicht den Zensurstandards in vielen Ländern genügt. Dabei sind die Schulstandards oft noch einmal separat von den für die Allgemeinheit geltenden gesetzlichen Regelungen; in US-Schulen werden bestimmte Bücher wie Huckleberry Finn z.B. regelmäßig verboten. Dass die Schulen im Bible-Belt nicht allzu froh darüber sein dürften, im Wikipedia-Artikel über die Klitoris ein buntes Farbfoto mit Zoom zu finden, versteht sich von selbst.
Assimilation Now
In seinem Essay "As We May Think" machte sich Vannevar Bush auch darüber Gedanken, wie es weitergehen könnte, wenn Spracherkennung und Displays perfektioniert sind.
"Wann immer wir Daten schaffen oder aufnehmen, muss dies durch einen der Sinne vonstatten gehen -- durch den Tastsinn, wenn wir Tasten berühren, das Orale, wenn wir sprechen oder zuhören [sic], das Visuelle, wenn wir lesen. Wäre es nicht denkbar, dass wir eines Tages den direkten Weg gehen?"
Das Gehirn, so Bush, arbeite mit elektrischen Signalen - wie verschwenderisch sei es, zunächst Vibrationen zu erzeugen, um einen Ton hörbar zu machen, wenn man die gleichen Informationen direkt an das Hirn schicken könnte. Neurale Interfaces seien durchaus im Bereich des Denkbaren.
|
Jeder Fan des Star Trek Science-Fiction-Universums wird bei solchen Worten hellhörig: In der Welt von Captain Picard und Wesley Crusher sind die Oberbösewichte organisch-mechanische und stets miteinander vernetzte "Cyborgs", kurz "Borg" genannt. Ihr einziges Ziel ist die "Assimilierung" aller anderen Lebensformen ins kollektive Bewusstsein, um sich deren Wissen und ihre Kultur anzueignen. Winzige Nano-Roboter werden in den Blutkreislauf der Opfer injiziert, die daraufhin mechanisiert und Teil des kollektiven Systems werden.
Doch die Borg wurden bewusst als finstere, gewalttätige Kultur ohne Emotionen dargestellt. Die zugrundeliegende Idee des kollektiven Bewusstseins fasziniert und amüsiert gleichermaßen. War nicht der erste Schritt in diese Richtung bereits getan, als der erste Mensch ein verständliches Wort sprach? Ist nicht bereits das internationale Telefonnetz ein gigantischer Schritt zur Verknüpfung von Gedanken? Wenn tragbare Computer, PDAs und "smarte Telefone" schon bald allgegenwärtig sind, wenn Bandbreite verfügbar ist, um auch die emotional bedeutsamen Videoinformationen in Echtzeit zu transportieren, wenn die Software das jederzeitige, parallele Schaffen von Wissen erlaubt, wird es dann erste Borg-artige Subkulturen geben, die sich offen dazu bekennen, in einem Zustand der ständigen Vernetztheit zu leben? Sind solche Fantasien nur die Ausgeburt emotional vernachlässigter Hacker, die sich im Netz nach Wärme und Zuwendung sehnen? Oder sind sie ein unvermeidlicher, notwendiger Schritt für eine Zivilisation der nächsten technologischen Entwicklungsstufe? Über welche Kultur wird die Wikipedia von morgen schreiben?
Sobald die Vernetzung direkt und unmittelbar wird, sobald die Rede von Hirnen ist und nicht mehr von Menschen, wird manch ein Beobachter entsetzt das Weite suchen. Soziologen, die noch einen Realitätsbezug haben, werden dem Rest der Welt unterstellen, ihn nun offenbar vollständig verloren zu haben und sich entnervt dem Studium von Pantoffeltierchen zuwenden. Doch in der Geschichte der Menschheit gibt es wohl kaum ein Phänomen, das so unaufhörlich fortzuschreiten scheint wie die zunehmende Vernetzung unserer Kultur. Die Interaktion in virtuellen Ballerwelten hat für viele Jugendliche bereits das Fußballspiel abgelöst - werden eines Tages nur noch die Gehirne tanzen?







{kind=link}